metaQuantome 3: Taxonomy

 Subina Mehta
Subina Mehta Timothy J. Griffin
Timothy J. Griffin Pratik Jagtap
Pratik Jagtap Emma Leith
Emma Leith Marie Crane
Marie Crane Praveen Kumar
Praveen KumarOverviewQuestions:Objectives:
How do I look at differentially expressed taxa?
Can we get top 5 or 10 taxa present in the sample?
How can I visualize my results?
Requirements:
A taxonomy and quantitational analysis of metaproteomic mass spectrometry data.
- Introduction to Galaxy Analyses
- Proteomics
- metaQuantome 1: Data creation: tutorial hands-on
Time estimation: 1 hourLevel: Intermediate IntermediateSupporting Materials:Last modification: Oct 18, 2022
 Questions:
Questions:
Introduction
metaQuantome software suite Easterly et al. 2019 was developed by the Team for quantitative and statistical analysis of metaproteomics data. For taxonomic and functional expression analysis within the microbial community, metaQuantome leverages peptide-level quantitative information to generate visual outputs for data interpretation. It also generates outputs that help in understanding the taxonomic contribution to a selected function as well as functions expressed by selected taxonomic group.
In this tutorial, we will learn specifically about the metaQuantome Taxonomy workflow. In particular, we will learn about how peptide-level quantitation and associated taxonomic information can be used to generate bar plots (for taxonomic composition), volcano plots (to detect differentially expressed taxa) and heatmap cluster analysis.
To demonstrate the use of this workflow, we have used a thermophilic biogas reactor dataset wherein municipal food waste and manure is digested to generate methane gas (Delogu et al. 2020). After one round in the reactor, the microbial community was simplified and enriched via serial dilution. This inoculum was then transferred to a solution of cellulose from Norwegian Spruce and incubated at 65°C. Triplicate samples were taken in a time series from 0 to 43 hours after inoculation and mass spectrometry data was acquired on a Q-Exactive (Thermo) mass spectrometer. For this training, we have chosen three time points (8 hours, 18 hours and 33 hours) from this dataset.
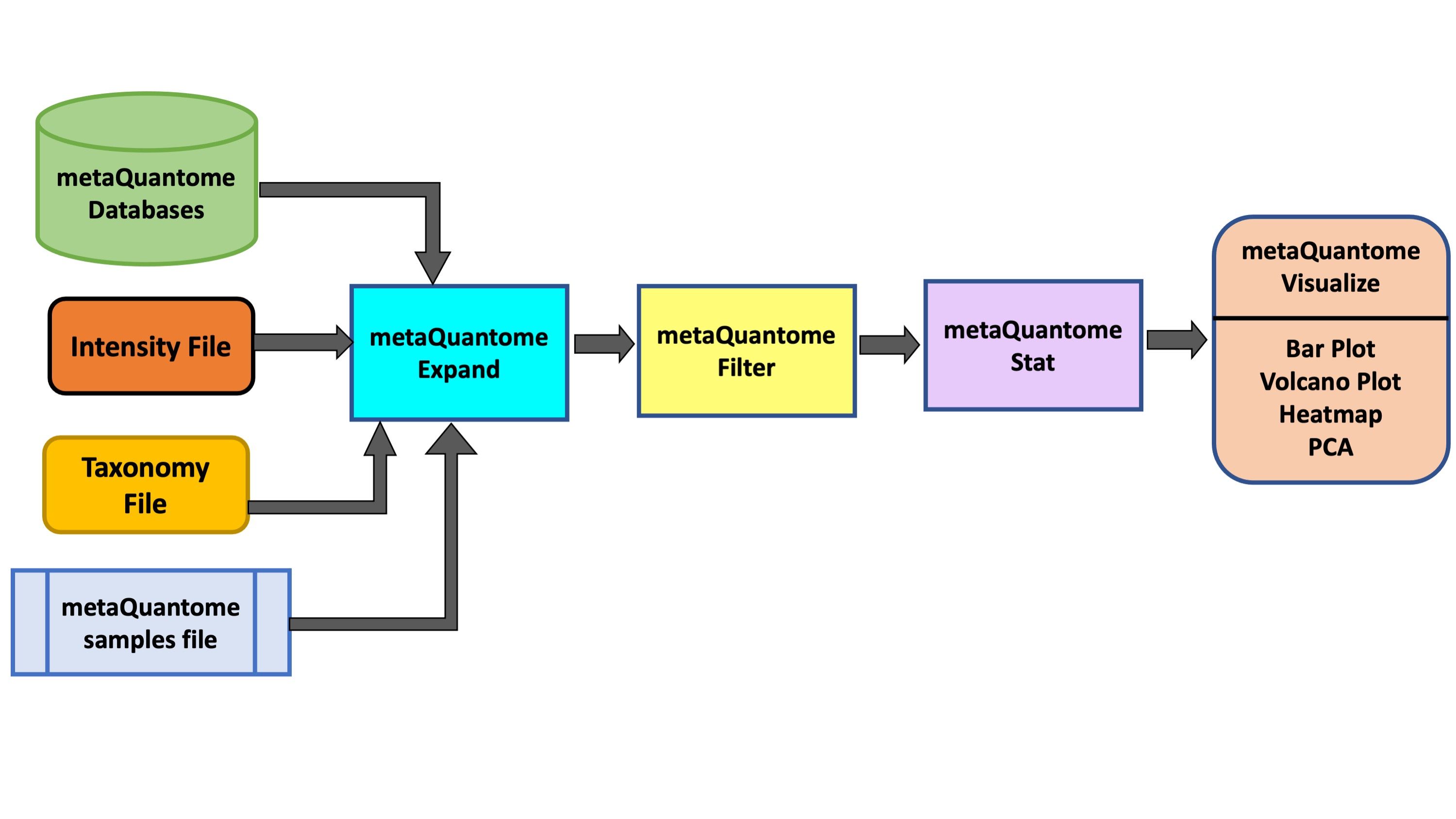
AgendaIn this tutorial, we will cover:
Pretreatments
The first step in this tutorial is to get the data from the Zenodo link provided and make sure that it is in the correct format.
Get data
Hands-on: Data upload
Create a new history for this tutorial and give it a meaningful name.
Click the new-history icon at the top of the history panel.
If the new-history is missing:
- Click on the galaxy-gear icon (History options) on the top of the history panel
- Select the option Create New from the menu
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
Import the files from Zenodo: a Functional File and an Intensity file.
https://zenodo.org/record/4110725/files/Intensity-File.tabular https://zenodo.org/record/4110725/files/Taxonomy-File.tabular
- Copy the link location
Open the Galaxy Upload Manager (galaxy-upload on the top-right of the tool panel)
- Select Paste/Fetch Data
Paste the link into the text field
Press Start
- Close the window
Alternatively, import the files from the shared data library (
GTN - Material->proteomics->metaQuantome 3: Taxonomy)As an alternative to uploading the data from a URL or your computer, the files may also have been made available from a shared data library:
- Go into Shared data (top panel) then Data libraries
- Navigate to the correct folder as indicated by your instructor
- Select the desired files
- Click on the To History button near the top and select as Datasets from the dropdown menu
- In the pop-up window, select the history you want to import the files to (or create a new one)
- Click on Import
Download metaQuantome Databases
Hands-on: Run metaQuantome databases
- metaQuantome: databases Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_db/metaquantome_db/2.0.0-0 with the following parameters:
- param-select “Databases to Download”:
Select All(NCBI Taxonomy Database, Gene Ontology Database and Enzyme Commission (EC) database)CommentmetaQuantome uses freely available bioinformatic databases to expand your set of direct annotations.
The databases are:
NCBI taxonomy database. consists of a list of all currently identified taxa and the relationships between them.
Gene Ontology (GO) term database. metaQuantome uses the go-basic.obo file and the metagenomics slim GO (subset of the full GO). More details are available at GO term website
ENZYME database with Enzyme Classification (EC) numbers. This database classifies enzymes and organizes the relationships between them.
Question
- Why is it necessary to download metaQuanome databases?
- Can these databases be downloaded from other sources?
- metaQuantome databases help the metaQuantome:expand tool to co-relate information your have provided in your input files according to the GO term, taxa or EC databases and its relationship .
- For metaQuantome, we use freely available databases. This module downloads the most recent releases of the specified databases and stores them in a single file, which can then be accessed by the rest of the metaQuantome modules. For reference, the taxonomy database is the largest (~500 Mb), while the GO and EC databases are smaller: ~34 Mb and ~10Mb, respectively. Also, note that the databases will be stored in the history so that the date of download can be referenced later. Thus, the databases will not be modified, except for the NCBI database.
Create metaQuantome sample file
The create samples file module is used to generate the samples file input file for the metaQuantome workflow. This input file is used to specify the column names used for each experimental group. These column names are referenced when handling the input data and performing statistical analysis.
Hands-on: Create an experimental Design file for sorting samples
- metaQuantome: create samples file Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_sample/metaquantome_sample/2.0.0-0 with the following parameters:
- param-select “Sample file creation method”:
Manually specify experimental conditions and samples- In “Insert Samples”:
- “1.Samples”:
- “Group Name”:
T2
- “Column”:
T2_A1,T2_B1- “2.Samples”:
- “Group Name”:
T4
- “Column”:
T4A_1,T4B_1- “3.Samples”:
- “Group Name”:
T7
- “Column”:
T7A_1,T7B_1
Run metaQuantome
metaQuantome: expand
The expand module is the first analysis step in the metaQuantome analysis workflow, and can be run to analyze differently expressed Taxa in the samples. In taxonomy mode, the following information is required apart from metaQuantome databases and samples file: a tab-separated taxonomy annotation file, with a peptide column and a taxonomy annotation column. The taxonomic annotations should be the lowest common ancestor (LCA) for each peptide, preferably given as NCBI taxonomy IDs.
- The name of the peptide column in the taxonomic annotation file (
peptide) - The name of the taxonomy annotation column in the taxonomy annotation file (
taxon_id) - The name of the peptide column in the Intensity file (
peptide)
Hands-on: Run metaQuantome expand
- metaQuantome: expand Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_expand/metaquantome_expand/2.0.0-0 with the following parameters:
- param-file “Database Archive File”:
metaQuantome databases(output of metaQuantome: database tool)- param-file “Samples file”:
metaQuantome: create samples_file(output of metaQuantome: create samples file tool)- “Mode”:
Taxonomic analysis
- param-file “Taxonomy file”:
Taxonomy File(Input dataset)- “Taxonomy file: peptide column name”:
peptide- “Taxonomy column name”:
taxon_id- param-file “Intensity file”:
Intensity File(Input dataset)
- “Intensity file: peptide column name”:
peptideRename galaxy-pencil the output file to
metaQuantome expand.CommentThe structure of the output file depends on the analysis mode and the experimental design, but the columns generally look like this, with one row for each term:
term id info about term. (one or more columns) mean term intensity (by sample group) term intensity (by sample) number of unique peptides (by sample) number of sample children in each sample term1 name, rank, etc. note that this is the log2 of the mean intensity this is the log2 of term intensity in each sample. Missing data is coded as NA. integer. 0 is coded as NA integer. 0 is coded as NA
metaQuantome: filter
The filter module is the second step in the metaQuantome workflow. The filter module filters the expanded terms to those that are representative of the data according to the sample parameters the user has specified.
Hands-on: Filtering the expanded data
- metaQuantome: filter Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_filter/metaquantome_filter/2.0.0-0 with the following parameters:
- “Mode”:
Taxonomic analysis- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- param-file “metaquantome expand file”:
metaQuantome:expand(output of metaQuantome: expand tool)- “min_peptides”:
1- “min_pep_nsamp”:
1- “min_children_non_leaf”:
2- “min_child_nsamp”:
1- “qthreshold”:
2Rename galaxy-pencil the output file to
metaQuantome:Filter.CommentTo learn more about the filter module please read the metaQuantome paper published by Galaxy-P Easterly et al. 2019.
Question
- Can we change the filter parameters?
- The parameters can be changed according to the experimental design or depending on the data.
metaQuantome: stat
Hands-on: Statistical analysis of the filtered data on multiple conditions.
- metaQuantome: stat Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_stat/metaquantome_stat/2.0.0-0 with the following parameters:
- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- param-file “metaquantome expanded or filtered file”:
metaQuantome:Filter(output of metaQuantome: filter tool)- “Mode”:
Taxonomic analysis- “Name of the control sample group of control (used as denominator for fold change evaluation).”:
T2- “Statistical test to perform”:
standard t-test (parametric)- “Perform paired tests”:
YesRename galaxy-pencil the output file to
metaQuantome:stat.CommentIn this tutorial, we have used the sample T2 as the control group for fold change evaluation. The users have the ability to choose their own control sample group. The initial version of the metaQuantome stat module could only process 2 conditions at a time. However, the new update of metaQuantome has the ability to perform statistical analysis across multiple conditions.
Visualize your Data
The outputs of the visualization module of metaQuantome are high-quality, publication-ready visualizations: barplots for the analysis of a single sample or experimental condition and differential abundance analysis, volcano plots, heatmaps, and principal components analysis for comparisons between two or more experimental conditions. Here were are showing 2 visualizations: Barplot and Volcano Plot. The Heatmap and PCA plot for multiple conditions are under development. There are two outputs of the visualization tool : an HTML file (figure) and a tabular output containing the plot data.
metaQuantome: visualize
Hands-on: Bar chart visualization of Taxonomy in T2 sample.
- metaQuantome: visualize Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_viz/metaquantome_viz/2.0.0-0 with the following parameters:
- param-file “Tabular file from metaQuantome stats or metaQuantome filter”:
metaQuantome:stat(output of metaQuantome: stat tool)- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- “Mode”:
Taxonomic analysis
- “Plot type”:
Bar Chart (bar)
- “Taxonomic rank to restrict to in the plot”:
genus- “Mean intensity column name”:
T2_meanCommentThe user has a choice to run Bar plot for T2, T4 and T7 to know the top 5 or 10 most differently expressed taxonomy.
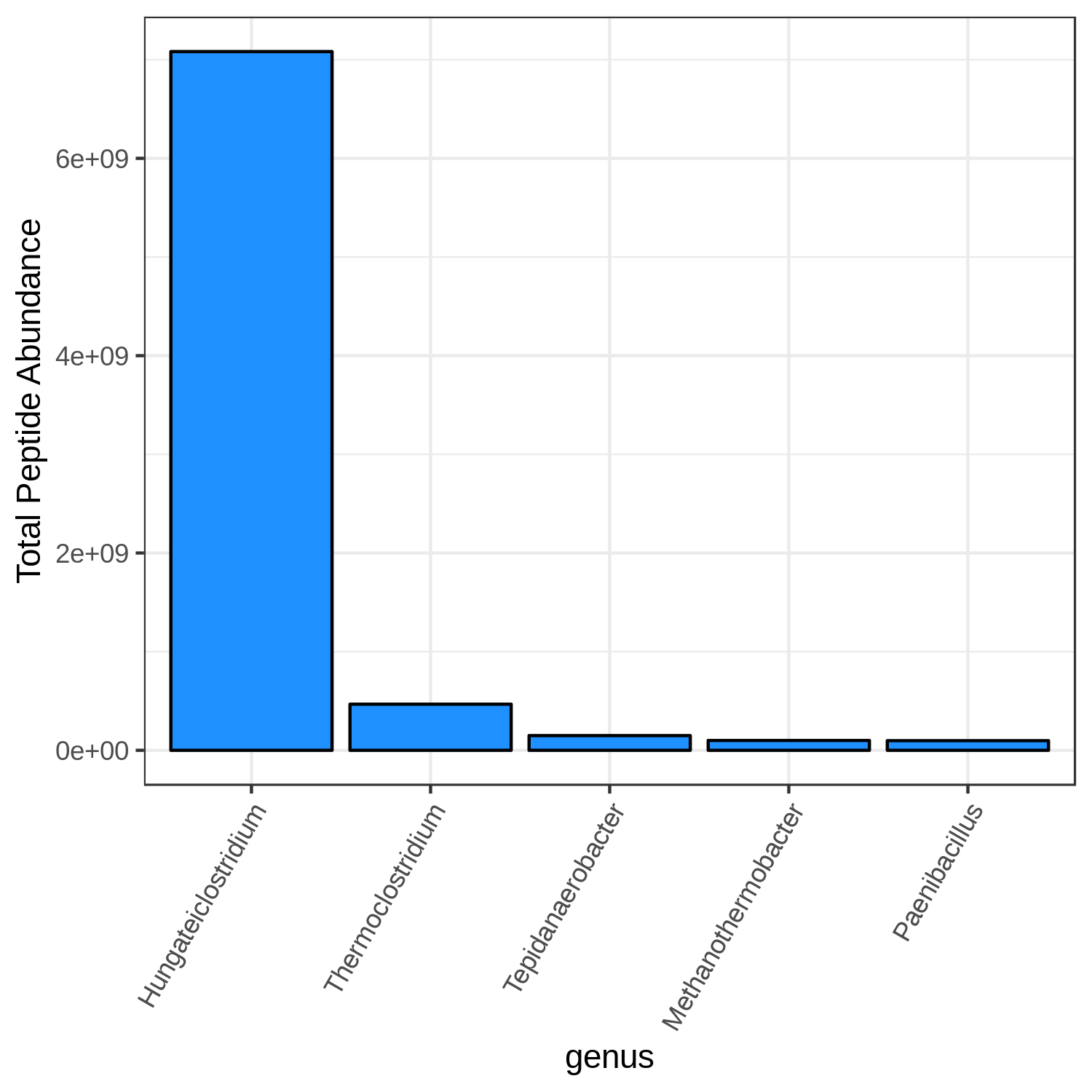
Question
- Can we select any color for the bar chart?
- Can we increase the number of terms to display?
- Yes, the available colors are blue, orange, yellow, violet, black and red.
- Yes, the user can choose their own number, however, the larger the display numbers are the dimensions of the image has to be adjusted accordingly.
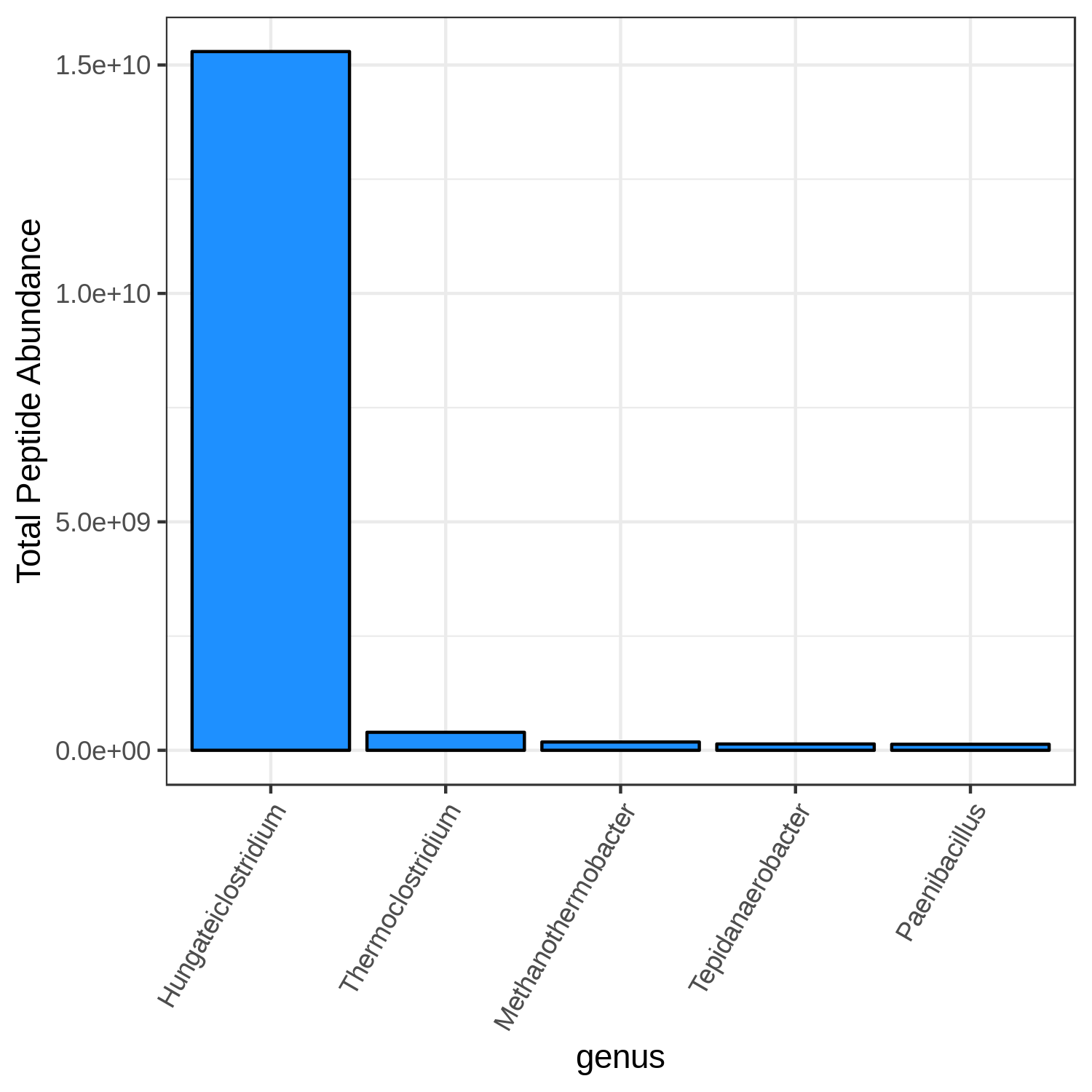
Hands-on: Bar chart visualization of Taxonomy in T7 sample.
- metaQuantome: visualize Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_viz/metaquantome_viz/2.0.0-0 with the following parameters:
- param-file “Tabular file from metaQuantome stats or metaQuantome filter”:
metaQuantome:stat(output of metaQuantome: stat tool)- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- “Mode”:
Taxonomic analysis
- “Plot type”:
Bar Chart (bar)
- “Taxonomic rank to restrict to in the plot”:
genus- “Mean intensity column name”:
T7_mean
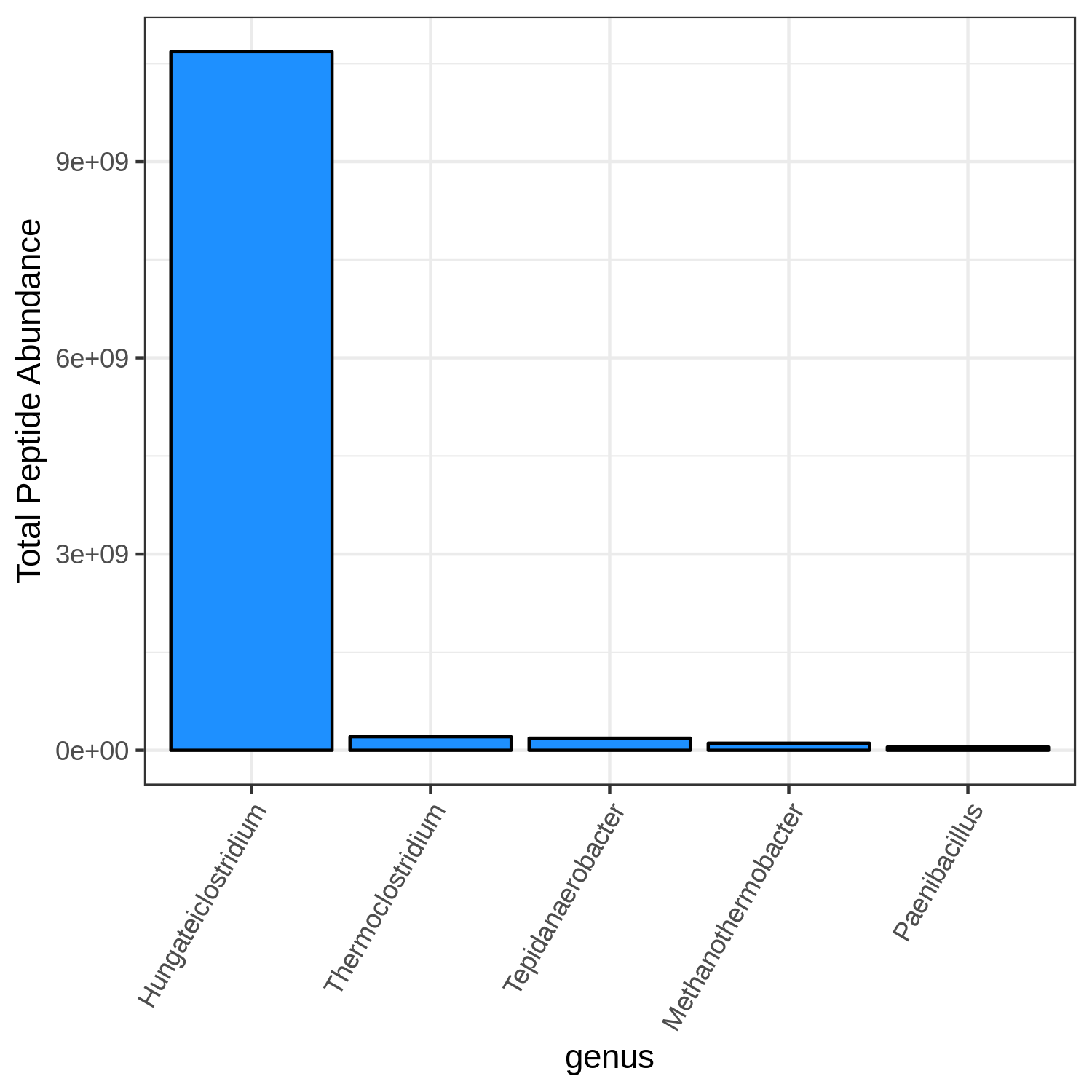
Hands-on: Bar chart visualization of Taxonomy in T4 sample.
- metaQuantome: visualize Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_viz/metaquantome_viz/2.0.0-0 with the following parameters:
- param-file “Tabular file from metaQuantome stats or metaQuantome filter”:
metaQuantome:stat(output of metaQuantome: stat tool)- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- “Mode”:
Taxonomic analysis
- “Plot type”:
Bar Chart (bar)
- “Taxonomic rank to restrict to in the plot”:
genus- “Mean intensity column name”:
T4_mean
metaQuantome: visualize Volcano Plots
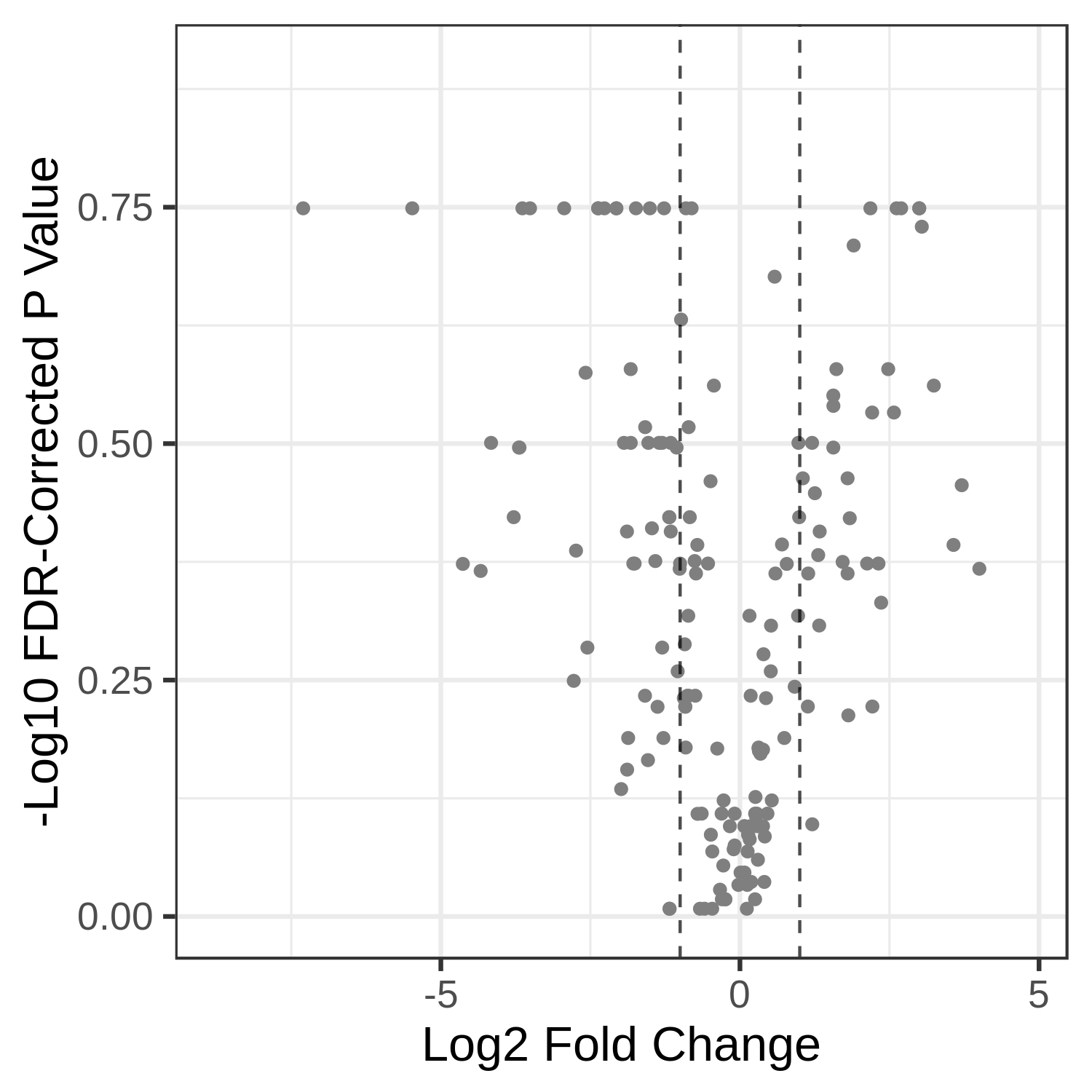
Hands-on: Volcano Plot visualization of the data T4 and T2.
- metaQuantome: visualize Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_viz/metaquantome_viz/2.0.0-0 with the following parameters:
- param-file “Tabular file from metaQuantome stats or metaQuantome filter”:
metaQuantome:stat(output of metaQuantome: stat tool)- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- “Mode”:
Taxonomic analysis
- “Plot type”:
Volcano Plot (volcano)
- “Name of the fold change column in the stat dataframe”:
log2fc_T4_over_T2- “Name of the Corrected p-value column in the stat dataframe”:
corrected_p_T4_over_T2- param-select “Flip the fold change (i.e., multiply log fold change by -1)”:
NoCommentHere, we show metaQuantome’s Taxonomy differential abundance volcano plot. The user may select the significance threshold (0.05 by default), and terms with statistically significant fold changes are colored green and labeled. However, we can currently only compare two conditions at a time. Here we have compared T4 and T2 time points. The user can also perform comparison of T7 and T2.
Hands-on: Volcano Plot visualization of the data T7 and T2.
- metaQuantome: visualize Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/metaquantome_viz/metaquantome_viz/2.0.0-0 with the following parameters:
- param-file “Tabular file from metaQuantome stats or metaQuantome filter”:
metaQuantome:stat(output of metaQuantome: stat tool)- param-file “Samples file”:
metaQuantome:create samples_file(output of metaQuantome: create samples file tool)- “Mode”:
Taxonomic analysis
- “Plot type”:
Volcano Plot (volcano)
- “Name of the fold change column in the stat dataframe”:
log2fc_T7_over_T2- “Name of the Corrected p-value column in the stat dataframe”:
corrected_p_T7_over_T2
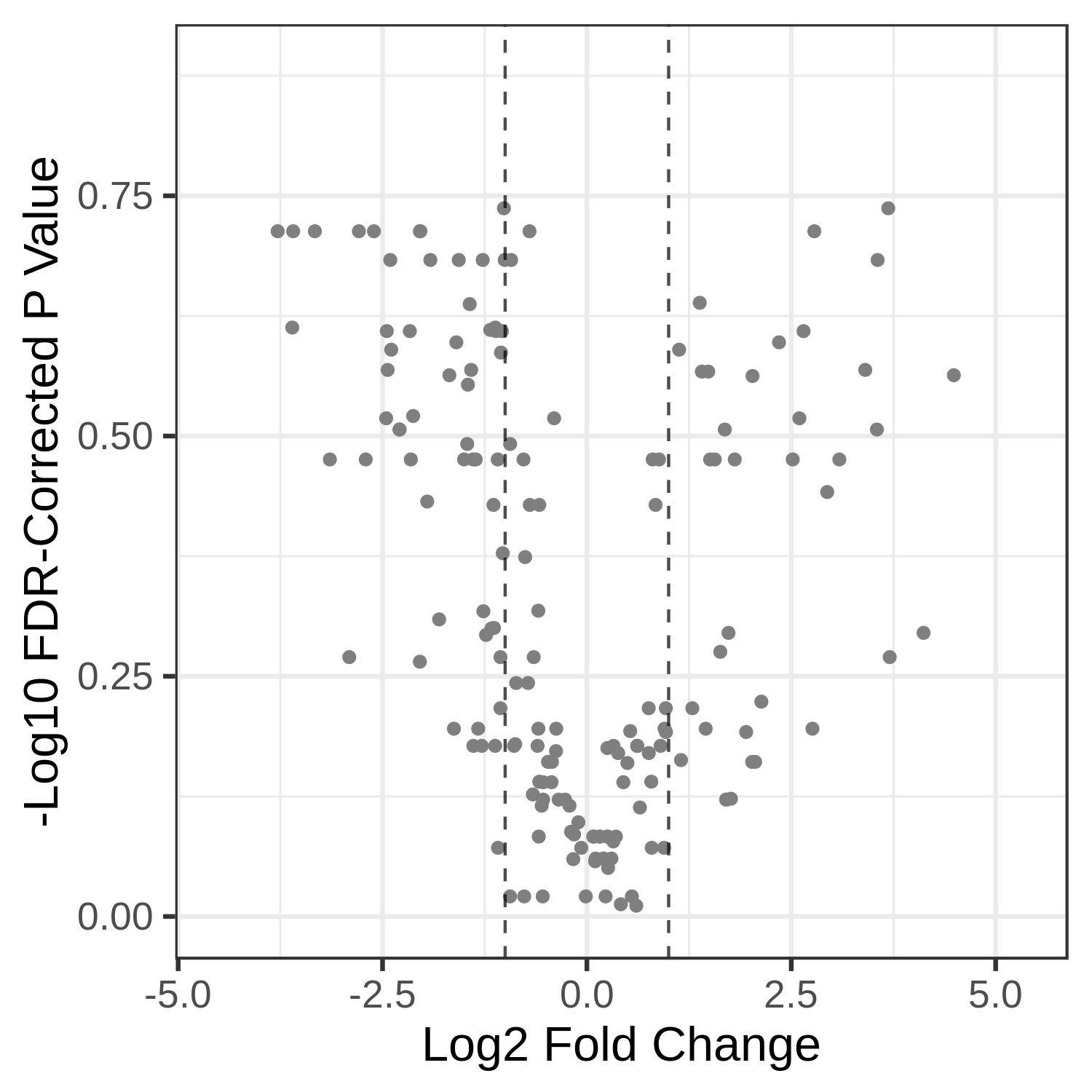
Question
- Can we choose to Flip the fold change?
- Certainly, the user has the ability to flip the fold changes.
Conclusion
This completes the walkthrough of the metaQuantome taxonomy workflow. This tutorial is a guide to run the metaQuantome modules and can be used for metaproteomics research. Here, we have incorporated only two visualization modules in this workflow but we will make the heatmap and PCA plot also available. Researchers can use this workflow with their data also, please note that the tool parameters and the workflow will be needed to be modified accordingly. Also, refer to the metaQuantome data creation workflow to understand how to make files metaQuantome compatible.
This workflow was developed by the Galaxy-P team at the University of Minnesota. For more information about Galaxy-P or our ongoing work, please visit us at galaxyp.org
Key points
All the inputs should have one column in common i.e. peptides.
Learning different tools such as Unipept, MEGAN, MetaGOmics etc. for taxonomic annotation of peptides will benefit.
Frequently Asked Questions
Have questions about this tutorial? Check out the tutorial FAQ page or the FAQ page for the Proteomics topic to see if your question is listed there. If not, please ask your question on the GTN Gitter Channel or the Galaxy Help ForumUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
- Easterly, C. W., R. Sajulga, S. Mehta, J. Johnson, P. Kumar et al., 2019 metaQuantome: An Integrated, Quantitative Metaproteomics Approach Reveals Connections Between Taxonomy and Protein Function in Complex Microbiomes. Molecular & Cellular Proteomics 18: S82–S91. 10.1074/mcp.ra118.001240
- Delogu, F., B. J. Kunath, P. N. Evans, M. Ø. Arntzen, T. R. Hvidsten et al., 2020 Integration of absolute multi-omics reveals dynamic protein-to-RNA ratios and metabolic interplay within mixed-domain microbiomes. Nature Communications 11: 10.1038/s41467-020-18543-0
- Team, G.-P. Galaxy-P. http://galaxyp.org/
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Subina Mehta, Timothy J. Griffin, Pratik Jagtap, Emma Leith, Marie Crane, Praveen Kumar, 2022 metaQuantome 3: Taxonomy (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/metaquantome-taxonomy/tutorial.html Online; accessed TODAY
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{proteomics-metaquantome-taxonomy, author = "Subina Mehta and Timothy J. Griffin and Pratik Jagtap and Emma Leith and Marie Crane and Praveen Kumar", title = "metaQuantome 3: Taxonomy (Galaxy Training Materials)", year = "2022", month = "10", day = "18" url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/metaquantome-taxonomy/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Batut_2018, doi = {10.1016/j.cels.2018.05.012}, url = {https://doi.org/10.1016%2Fj.cels.2018.05.012}, year = 2018, month = {jun}, publisher = {Elsevier {BV}}, volume = {6}, number = {6}, pages = {752--758.e1}, author = {B{\'{e}}r{\'{e}}nice Batut and Saskia Hiltemann and Andrea Bagnacani and Dannon Baker and Vivek Bhardwaj and Clemens Blank and Anthony Bretaudeau and Loraine Brillet-Gu{\'{e}}guen and Martin {\v{C}}ech and John Chilton and Dave Clements and Olivia Doppelt-Azeroual and Anika Erxleben and Mallory Ann Freeberg and Simon Gladman and Youri Hoogstrate and Hans-Rudolf Hotz and Torsten Houwaart and Pratik Jagtap and Delphine Larivi{\`{e}}re and Gildas Le Corguill{\'{e}} and Thomas Manke and Fabien Mareuil and Fidel Ram{\'{\i}}rez and Devon Ryan and Florian Christoph Sigloch and Nicola Soranzo and Joachim Wolff and Pavankumar Videm and Markus Wolfien and Aisanjiang Wubuli and Dilmurat Yusuf and James Taylor and Rolf Backofen and Anton Nekrutenko and Björn Grüning}, title = {Community-Driven Data Analysis Training for Biology}, journal = {Cell Systems} }
Do you want to extend your knowledge? Follow one of our recommended follow-up trainings:
- Proteomics
- Metaproteomics tutorial: tutorial hands-on
- metaQuantome 2: Function: tutorial hands-on