Understanding Galaxy history system
 Anton Nekrutenko
Anton Nekrutenko Martin Čech
Martin Čech
 Helena Rasche
Helena RascheOverviewQuestions:Objectives:
How do Galaxy histories work?
Gain understanding on navigating and manipulating histories
Time estimation: 30 minutesLast modification: Jun 1, 2022
 Questions:
Questions:
When data is uploaded from your computer or analysis is done on existing data using Galaxy, each output from those steps generates a dataset. These datasets (and the output datasets from later analysis on them) are stored by Galaxy in Histories.
The Current History
All users have one ‘current’ history, which can be thought of as a workspace or a current working directory in bioinformatics terms. Your current history is displayed in the right hand side of the main ‘Analyze Data’ Galaxy page in what is called the history panel.

The history panel displays output datasets in the order in which they were created, with the oldest/first shown at the bottom. As new analyses are done and new output datasets are generated, the newest datasets are added to the top of the the history panel. In this way, the history panel displays the history of your analysis over time.
Users that have registered an account and logged in can have many histories and the history panel allows switching between them and creating new ones. This can be useful to organize different analyses.
Anonymous users (if your Galaxy allows them) are users that have not registered an account. Anonymous users are only allowed one history. On our main, public Galaxy server, users are encouraged to register and log in with the benefit that they can work on many histories and switch between them.
The histories of anonymous users are only associated through your browser’s session. If you close the browser or clear you sessions - that history will be lost! We can not recover it for you if it is.
Current history controls
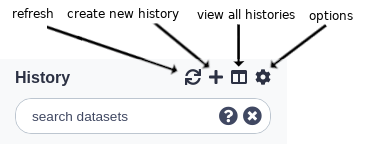
Above the current history panel are three buttons: the refresh, history options, and ‘view all histories’ button.
- The ‘refresh’ button will entirely reload the history being viewed. This can be helpful if you believe the history interface needs to be updated or isn’t updating properly.
- The ‘create new history’ button will create an empty history.
- The ‘view all histories’ button sends you to the interface for managing multiple histories.
- The ‘history options’ button opens the history options menu which allows you to perform history-related tasks.
History Information
Histories also store information in addition to the datasets they contain. They can be named/re-named, tagged, and annotated.
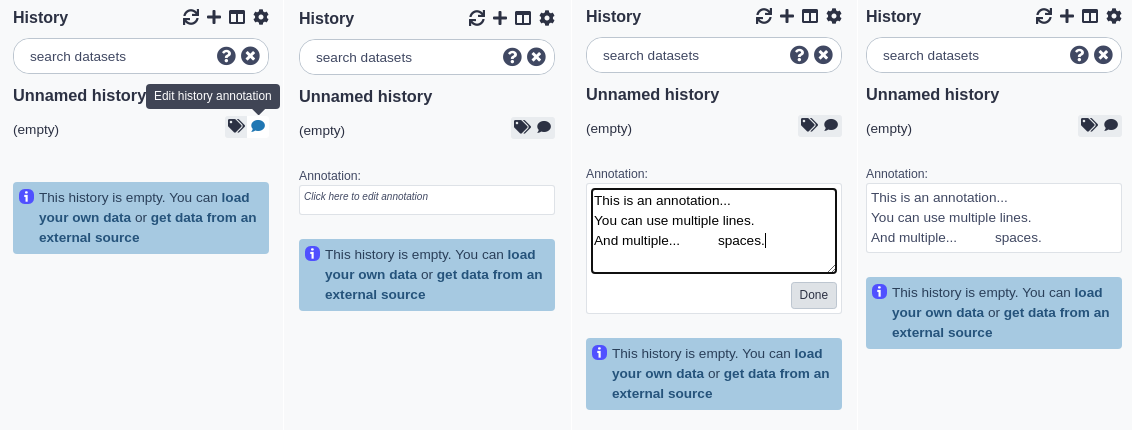
Renaming a history
All histories begin with the name ‘Unnamed history’. Non-anonymous users can rename the history as they see fit:
- Click the existing name. A text input field will appear with the current name.
- Enter a new name or edit the existing one.
- Press Enter to save the new name. The input field will disappear and the new history name will display.
- To cancel renaming, press Esc or click outside the input field.
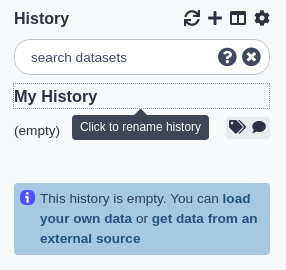
Tagging a history
Tags are short pieces of text used to describe the thing they’re attached to and many things in Galaxy can be tagged. Each item can have many tags and you can add new tags or remove them at any time. Tags can be another useful way to organize and search your data. For instance, you might tag a history with the type of analysis you did in it: ‘assembly’ or ‘variants’. Or you may tag them according to data sources or some other metadata: ‘long-term-care-facility’ or ‘yellowstone park:2014’.
Note: It is recommended to replace spaces in tags with _ or -. Although spaces are allowed in tags for histories, they are removed from the tags for datasets.
To tag a history:
- Click the tag button at the top of the history panel. An input field showing existing tags (if any) will appear.
- Begin typing your new tag in the field. Any tags that you’ve used previously will show below your partial entry - allowing you to use this ‘autocomplete’ data to re-use your previous tags without typing them in full.
- Press enter or select one of the previous tags with your arrow keys or mouse.
- To remove an existing tag, click the small ‘X’ on the tag or use the backspace key while in the input field.
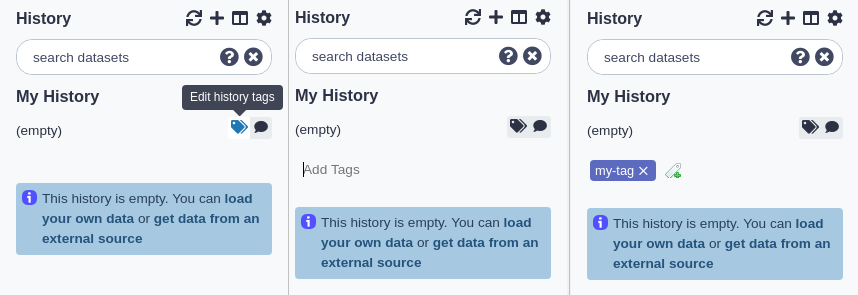
Annotating a history
Sometimes tags and names are not enough to describe the work done within a history. Galaxy allows you to create history annotations: longer text entries that allow for more formatting options. The formatting of the text is preserved. Later, if you publish or share the history, the annotation will be displayed automatically - allowing you to share additional notes about the analysis.
To annotate a history:
- Click the annotation button at the top of the history panel. A larger text section will appear displaying any existing annotation (or, if there’s none, italic text saying you can click on the control to create an annotation).
- Click the annotation section. A larger input field will appear.
- Add your annotations. Enter will move the cursor to the next line. (Tabs cannot be entered since the ‘Tab’ button is used to switch between controls on the page - tabs can be pasted in however).
- To save the annotation, click the ‘Done’ button.
History size
As datasets are added to a history, Galaxy will store them on the server. The total size of these files, for all the datasets in a history, is displayed underneath the history name. For example, if a history has 200 megabytes of dataset data on Galaxy’s filesystem, ‘200 MB’ will be displayed underneath the history name.
If your Galaxy server uses quotas, the total combined size of all your histories will be compared to your quota. If you’re using more than the quota allows, Galaxy will prevent you from running any new jobs until you’ve deleted some datasets and brought that total below the quota.
History Panel Datasets
Datasets in the history panel show the state of the job that has generated or will generate the data.
There are several different ‘states’ a dataset can be in:
- When you first upload a file or run a tool, the dataset will be in the queued state. This indicates that the job that will create this dataset has not yet started and is in line to begin.
- When the job starts, the dataset will be in the running state. The job that created these datasets is now running on Galaxy’s cluster.
- When the job has completed successfully, the datasets it generated will be in the ok state.
- If there’s been an error while running the tool, the datasets will be in the error state.
- If a previously running or queued job has been paused by Galaxy, the dataset will be in the paused state. You can re-start/resume paused jobs using the options menu above the history panel and selecting ‘Resume Paused Jobs’.
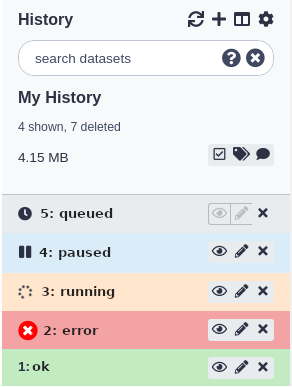
Datasets in the panel are initially shown in a ‘summary’ view, that only displays:
- A number indicating in what order (or what step) this dataset was created,
- The dataset name.
- A view button: click this to view the dataset contents in raw format in the browser.
- An edit button: click this to edit dataset properties.
- A delete button: click this to delete the dataset from the history (don’t worry, you can undo this action).
Note: some of the buttons above may be disabled if the dataset is in a state that doesn’t allow the action. For example, the ‘edit’ button is disabled for datasets that are still queued or running.

You can click the dataset name and the view will expand to show more details:
- A short description of the data.
- The file format.
- The reference sequence (or database) for the data.
- (Optionally) some information/output from the job that produced this dataset.
- A row of buttons that allow further actions on the dataset.
- A peek of the data: a couple of rows of data with the column headers (if available).
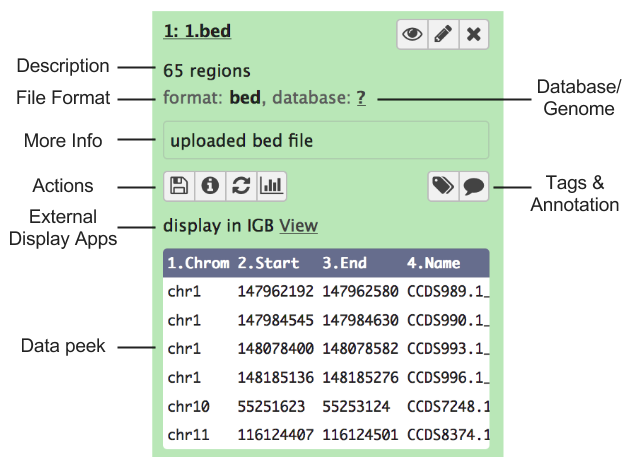
Note: many of these details are only displayed if the dataset has finished running, is in the ‘ok’ state, and is not deleted. Otherwise, you may only see a shorter message describing the dataset’s state (e.g. ‘this dataset is waiting to run’)
Managing Datasets Individually
Hiding and unhiding datasets
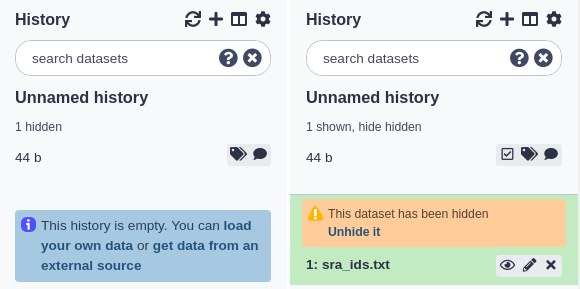
Some procedures in Galaxy such as workflows will often hide history datasets in order to simplify the history and hide intermediate steps of an automated analysis. These hidden datasets won’t normally appear in the history panel but theyre still mentioned in the history subtitle (the smaller, grey text that appears below the history name). If your history has hidden datasets, the number will appear there (e.g. ‘3 hidden’) as a clickable link. If you click this link, the hidden datasets are shown. Each hidden dataset has a link in the top of the summary view that allows you to unhide it. You can click that link again (which will now be ‘hide hidden’) to make them not shown again.
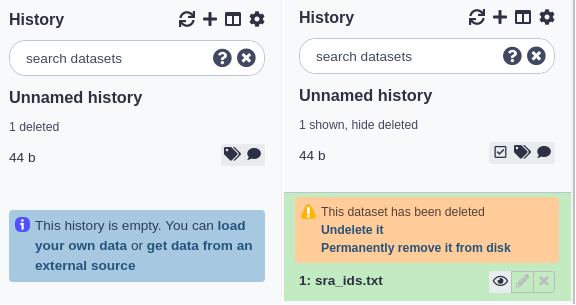
Deleting and undeleting datasets
You can delete any dataset in your history by clicking the delete button. This does not immediately remove the dataset’s data from Galaxy and it is reversible. When you delete a dataset from the history, it will be removed from the panel but (like hidden datasets) the total number of deleted datasets is shown in the history subtitle as a link. Clicking this link (e.g. ‘3 deleted’) will make the deleted datasets visible and each deleted dataset will have a link for manually undeleting it, above its title. You can click that link again (which will now be ‘hide deleted’) to make them not shown again.
Purging datasets and removing them permanently from Galaxy
If you are showing deleted datasets and your Galaxy allows users to purge datasets, you will see an additional link in the top of each deleted dataset titled ‘Permanently remove it from disk’. Clicking this will remove the file that contains that dataset’s data and will decrease the disk space used by the history. This action is not reversible and cannot be undone.
If your Galaxy doesn’t allow users to purge their datasets, you will not see that link.
Admins may purge your deleted datasets
Depending on the policy of your Galaxy server, administrators will often run scripts that search for and purge the datasets you’ve marked as deleted. Often, deleted datasets and histories are purged based on the age of the deletion (e.g. datasets that have been marked as deleted for 90 days or more). Check with the administrators of your Galaxy instance to find out the policy used.
Tagging datasets
There are two types of tags that can be used as an additional level of labeling for datasets: standard tags and hashtags (also known as name tags or propagating tags). The standard tags work similarly to history tags described above - they add another level of description to datasets making them easier to find:
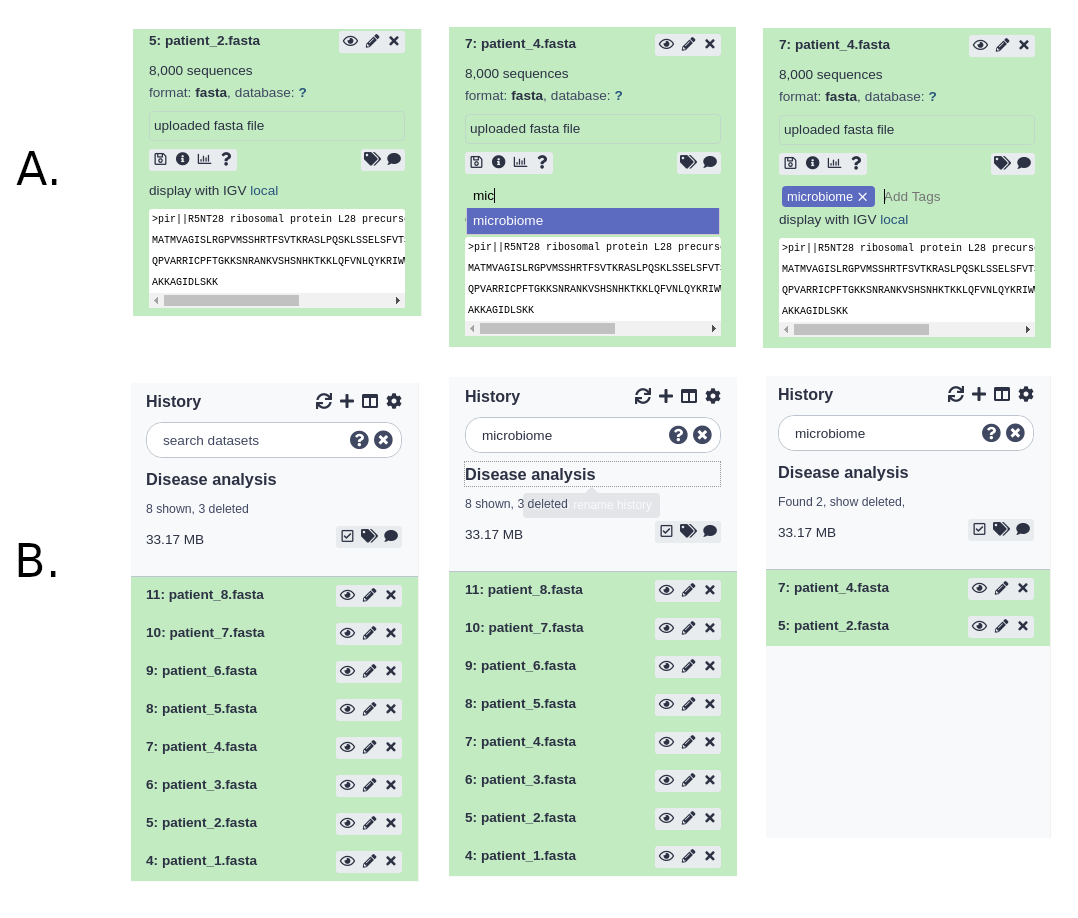
Hashtags are much more powerful as they are displayed in the history panel and propagate through the analysis:
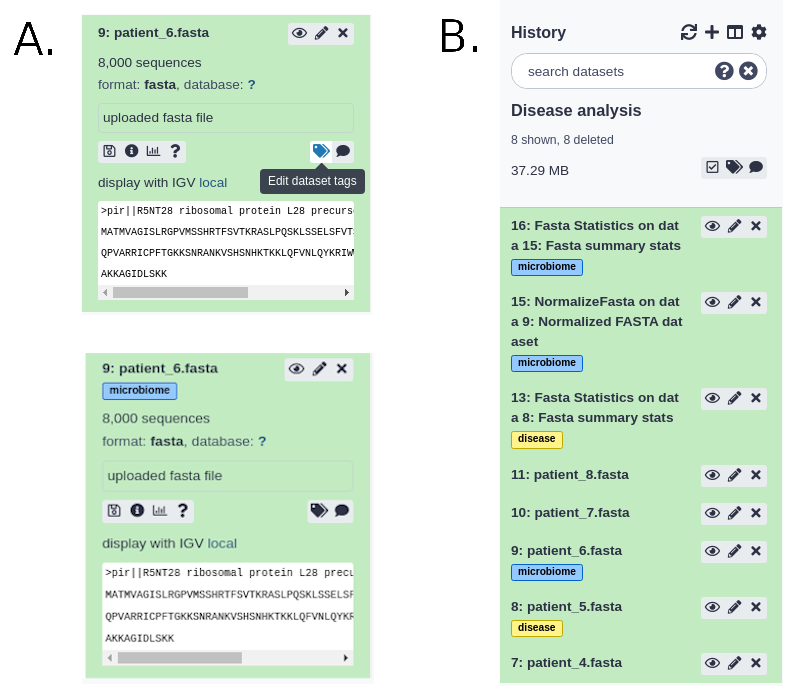
For more information on name tags, a video is available of their usage.
Managing Multiple Datasets Easily
Multi-selection
You can also hide, delete, and purge multiple datasets at once by multi-selecting datasets:
- Click the multi-select button containing the checkbox to the right of the history size.
- Checkboxes will appear inside each dataset in the history.
- Scroll and click the checkboxes next to the datasets you want to manage. You can also ‘shift+click’ to select a range of datasets.
- Click the ‘All’ button to select all datasets. Click the ‘None’ button to clear/remove all selections.
- Click the ‘For all selected…’ to choose the action. The action will be performed on all selected datasets, except for the ones that don’t support the action. That is, if an action doesn’t apply to a selected dataset - like deleting a deleted dataset - nothing will happen to that dataset, while all other selected datasets will be deleted.
- You can click the multi-select button again to hide the checkboxes again.
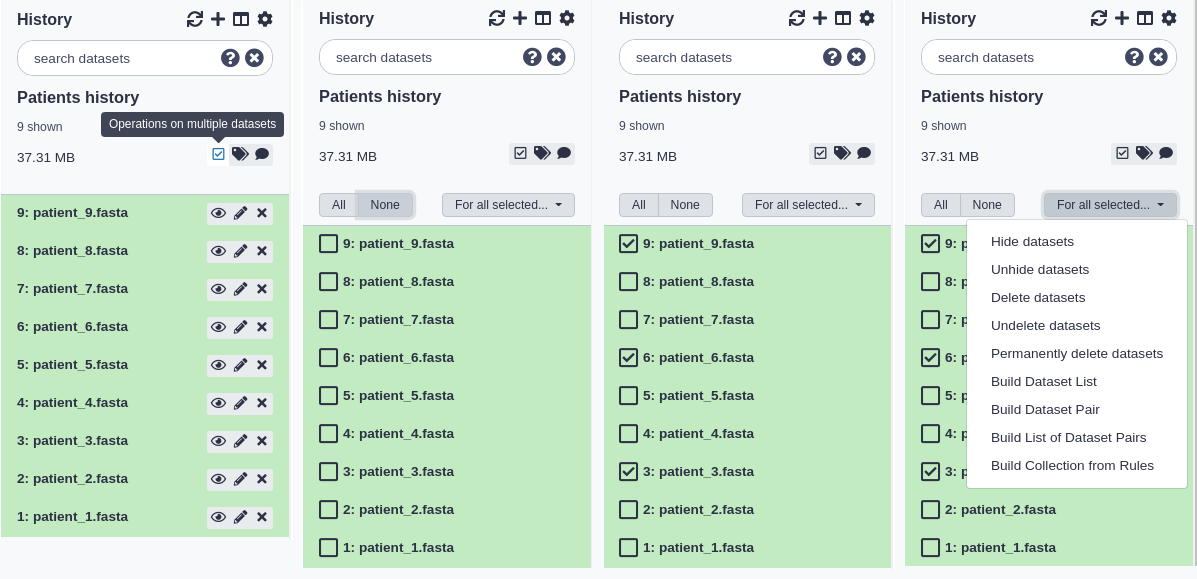
Basic Searching
You can filter what datasets are shown and search for datasets using the search bar at the top of the panel. Enter any text that a dataset you’d be looking for would contain, including:
- the name or part of the name
- any text (or partial text) from the info field
- the file format or reference database
- any text or partial text from the annotation or tags of a dataset
For example:
- To find all vcf files you might enter:
vcfalone. - To find all files whose names contain data 1, you can enter:
data 1 - To search for a VCF file named ‘VCF filter on data 1’ and tagged with ‘experiment_1’, you could enter:
vcf filter on data 1 experiment_1
Do I search for VCF or vcf? Searches are case-insensitive. For example,
VCFandvcfare equivalent.

Clearing a Search
You can clear a search and show all visible datasets by clicking the round ‘X’ button in the right of the search bar or - while entering text in the search bar - hitting the escape key (‘Esc’).
Advanced Searching
You can also specify dataset properties that you want to filter on. If you search with multiple properties, these are connected with ANDs, so datasets must match all provided attributes.
| Query | Results |
|---|---|
name="FASTQC on" |
Any datasets with “FASTQC on” in the title, but avoids items which have “FASTQC on” in other fields like the description or annotation. |
format=vcf |
Datasets with a specific format. Some formats are hierarchical, e.g. searching for fastq will find fastq files but also fastqsanger and fastqillumina files. You can see more formats in the upload dialogue. |
database=hg19 |
Datasets with a specific reference genome |
annotation="first of five" |
|
description="This is data of a Borneo Orangutan" |
for dataset summary description |
info="started mapping" |
for searching on job’s info field. |
tag=experiment1 tag=to_publish |
for searching on (a partial) dataset tag. You can repeat to search for more tags. |
hid=25 |
A specific history item ID (based on the ordering in the history) |
state=error |
To show only datasets in a given state. Other options include ok, running, paused, and new. |
history_content_type=collection |
Filter for collections |
Combining Searches Keyword searches can be combined:
database=mm10 annotation=successfulYou can enclose text with double quotes and include spaces:name="My Dataset" annotation="First run". Only the datasets that meet ALL search criteria will be shown.
If you find normal searching is showing too many datasets, and not what you’re looking for, try the advanced, keyword search.

Search and multi-select
It’s often useful to combine search and multi-select. Multi-selections will persist between searches, and the All/None buttons will only apply to the datasets currently shown with the given search.
So, for example, to select and manipulate two different sets of datasets:
- fastqsanger files tagged with ‘low quality’
- hg19 reference BAM files whose names contain “Output”
You can do the following steps:
- In the search bar, enter:
format=fastqsanger tag="low quality"and hit enter. - Click the multi-select button to show the checkboxes.
- Click the ‘All’ button to select all the fastqsanger files
- In the search bar, enter:
database=hg19 format=BAM name=outputand hit enter. - Click the ‘All’ button again to select all the BAM files.
- Clear the search using the clear button. All datasets are shown and both fastqsanger and BAM files are still selected.
- You can now perform some action on those two sets of datasets like building a collection or batch deleting them.
Undeleting … deleted histories
If you have not purged a history and have only deleted it, it is possible to ‘undelete’ it and reverse or undo the deletion. Since one of the purposes of deleting histories is to remove them from view, we’ll use the interface to specifically search for deleted histories and then to undelete the one we’re interested in.
There are two ways to do this currently: via the multi-history panel and through the saved histories page. The multi- history method is presented here:
Click the multi-history icon at the top right of the ‘Analyze Data’ (home) page. Note: you must be logged in to see the icon and use the multi-history page. You should see all the (non-deleted) histories that you’ve created.
Click the ‘…’ icon button in the grey header at the top of the page. You should see a dialog that presents some options for viewing the histories. Click the ‘include deleted histories’ option.
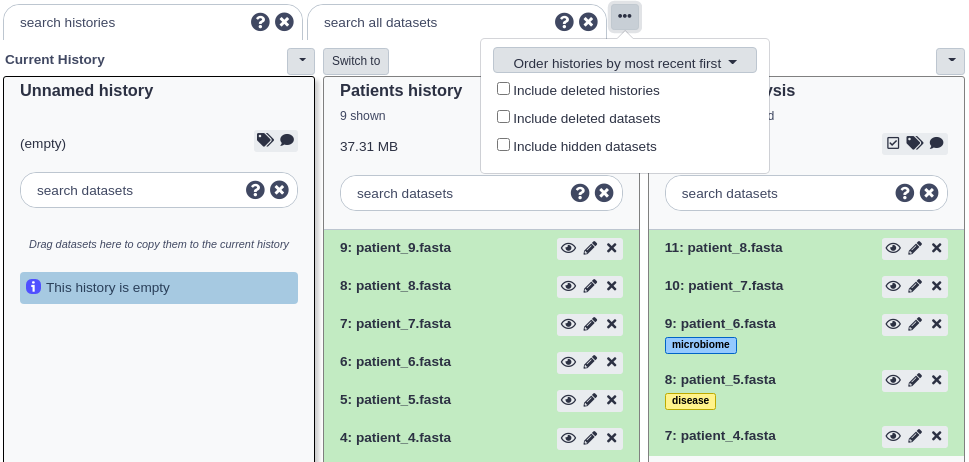
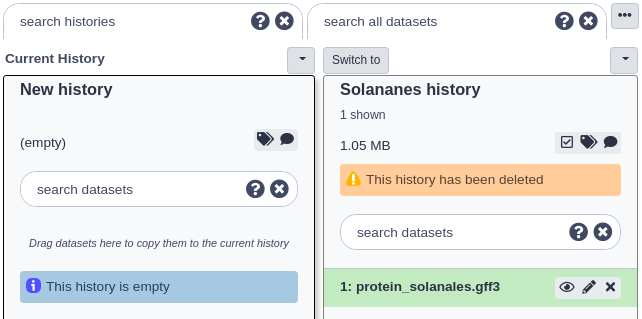
The page should reload and now both non-deleted and deleted histories will be displayed. Deleted histories will have a small message under their titles stating ‘This history has been deleted’.
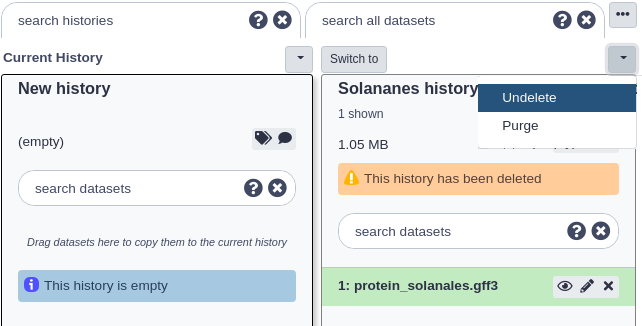
Now click the small button with the down arrow just above the deleted history you want to undelete. Then click the ‘Undelete’ option there. Your history should now be undeleted.
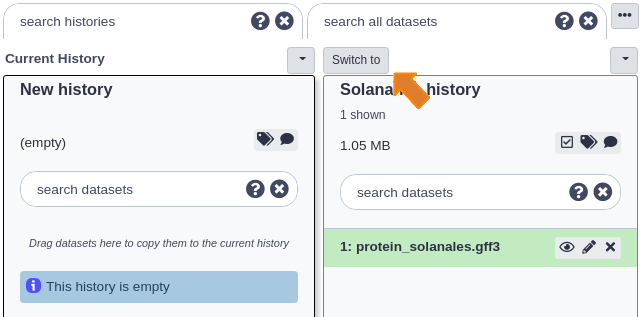
Click the ‘Switch to’ button at the top of that history and then click ‘done’ at the very top left to return to the ‘Analyze Data’ page.
Dataset Collections
When you have multiple datasets that will be sent through the same analysis, it can often be useful to place those datasets in a dataset collection. When collections are used as input when running a tool, you’re telling Galaxy to run that tool on each dataset in the collection using the same settings. This happens automatically and there’s no need to fill in the tool form more than once.
It may be helpful to metaphorically think of dataset collections as containers (or directories) in which you place datasets. To create a dataset collection from datasets in a history:
- Use multiselect to select the datasets you’d like to put into a collection.
- From the drop down menu labeled ‘For all selected…’, choose one of the collections types.
- Depending on the type you chose, some configuration and options may be displayed, and when you’ve chosen those, the collection is created and will show in the current history panel.
- Note: that your datasets are still shown in the history alongside the new collection. You can hide them if you like using the multiselect menu.
Viewing a dataset collection
You can view what datasets were inside a collection by clicking on the collection title. The history panel will be replaced by a list of the collection contents and each are expandable as a normal dataset in a history would be. You can click the ‘< Back to (you history name)’ link at the top to return to the history view (see below for examples).
The current collection types are: dataset pairs, dataset list, and list of dataset pairs - described below.
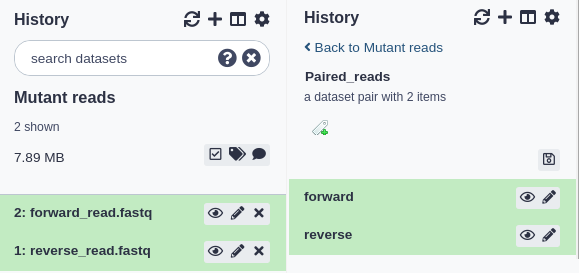
Dataset pairs
A common pattern of dataset files are pairs of read files - often some form of fastq files - where one file contains the forward reads and one file contains the reverse reads. Many bioinformatic tools accept these pairs and Galaxy can further simplify this by placing both files into on ‘Dataset Pair’ collection. Only two files will be added to the collection: forward and reverse.
Dataset list
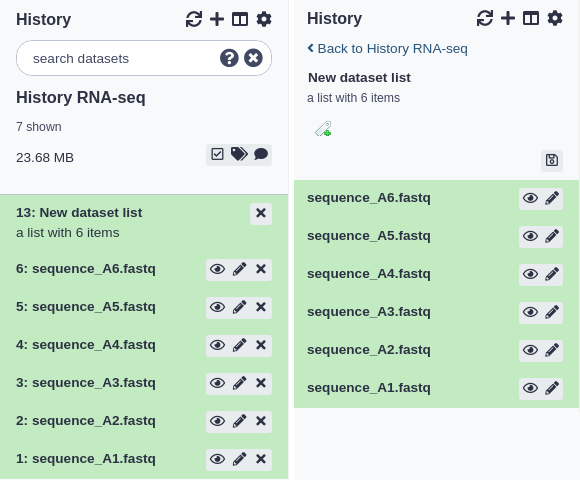
Choose ‘Dataset List’ when you have a set of files that are of the same type and will be run through some similar analysis. The datasets in a dataset list must have unique names (e.g. you cannot have two datasets in a dataset list with the name ‘1.bed’).
List of dataset pairs
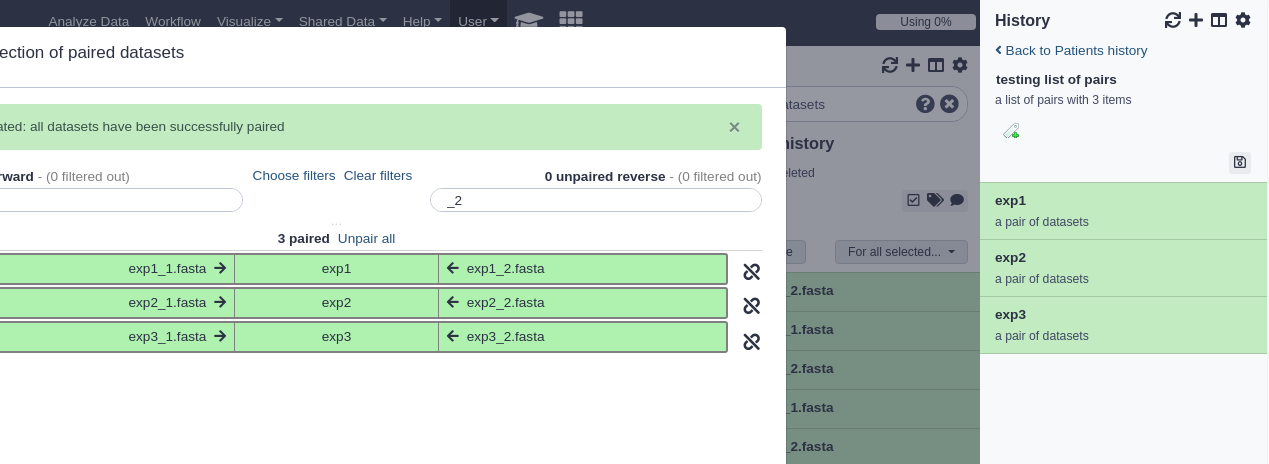
Think of this as a collection of collections: multiple dataset pairs contained in a dataset list. The interface used to create this is currently the most flexible and potentially most complicated. It will attempt to automatically pair datasets sent to the interface based on the dataset names. You are free to select your own pairs, however, and change the order of the collection. Click the help text at the top of the interface to see more information.
Key points
In Galaxy, data is stored in datasets and organized in histories
The right pane shows the current history. It displays the name of the history, the tags and annotations assigned to it, and the size of the data in it
The datasets are shown differently depending on their status: queued, running, ok, error, or paused
The summary view for each dataset can be expanded to show additional information
Datasets deleted are hidden from history. They can be restored to the history, or permanently deleted from the server, or purged. Purged files cannot be restored
Histories can also be deleted and purged, similar to datasets
Datasets can be organized into collections within a history with search and multi-select. Jobs applied to collections use the same settings for each dataset in the collection
Frequently Asked Questions
Have questions about this tutorial? Check out the FAQ page for the Using Galaxy and Managing your Data topic to see if your question is listed there. If not, please ask your question on the GTN Gitter Channel or the Galaxy Help ForumFeedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Anton Nekrutenko, Martin Čech, Helena Rasche, 2022 Understanding Galaxy history system (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/galaxy-interface/tutorials/history/tutorial.html Online; accessed TODAY
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{galaxy-interface-history, author = "Anton Nekrutenko and Martin Čech and Helena Rasche", title = "Understanding Galaxy history system (Galaxy Training Materials)", year = "2022", month = "06", day = "01" url = "\url{https://training.galaxyproject.org/training-material/topics/galaxy-interface/tutorials/history/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Batut_2018, doi = {10.1016/j.cels.2018.05.012}, url = {https://doi.org/10.1016%2Fj.cels.2018.05.012}, year = 2018, month = {jun}, publisher = {Elsevier {BV}}, volume = {6}, number = {6}, pages = {752--758.e1}, author = {B{\'{e}}r{\'{e}}nice Batut and Saskia Hiltemann and Andrea Bagnacani and Dannon Baker and Vivek Bhardwaj and Clemens Blank and Anthony Bretaudeau and Loraine Brillet-Gu{\'{e}}guen and Martin {\v{C}}ech and John Chilton and Dave Clements and Olivia Doppelt-Azeroual and Anika Erxleben and Mallory Ann Freeberg and Simon Gladman and Youri Hoogstrate and Hans-Rudolf Hotz and Torsten Houwaart and Pratik Jagtap and Delphine Larivi{\`{e}}re and Gildas Le Corguill{\'{e}} and Thomas Manke and Fabien Mareuil and Fidel Ram{\'{\i}}rez and Devon Ryan and Florian Christoph Sigloch and Nicola Soranzo and Joachim Wolff and Pavankumar Videm and Markus Wolfien and Aisanjiang Wubuli and Dilmurat Yusuf and James Taylor and Rolf Backofen and Anton Nekrutenko and Björn Grüning}, title = {Community-Driven Data Analysis Training for Biology}, journal = {Cell Systems} }