This tutorial uses ChIP-seq datasets from a study published by Wu et al. 2014. The goal of this study was to investigate “the dynamics of occupancy and the role in gene regulation of the transcription factor TAL1, a critical regulator of hematopoiesis, at multiple stages of hematopoietic differentiation.”
To this end, ChIP-seq experiments were performed in multiple mouse cell types including G1E - a GATA-null immortalized cell line derived from targeted disruption of GATA-1 in mouse embryonic stem cells - and megakaryocytes.
This dataset (GEO Accession: GSE51338) consists of biological replicate TAL1 ChIP-seq and input control experiments.
Input control experiments are used to identify and remove sampling bias, for example open/accessible chromatin or GC bias.
Because of the long processing time for the large original files, we have downsampled the original raw data files to include only reads that align to chromosome 19 and a subset of interesting genomic loci identified by Wu et al. 2014.
Table 1: Metadata for ChIP-seq experiments in this tutorial. SE: single-end.
As for any NGS data analysis, ChIP-seq data must be quality controlled before being aligned to a reference genome. For more detailed information on NGS quality control, check out the tutorial here.
Hands-on: Performing quality control
Create and name a new history for this tutorial.
Click the new-history icon at the top of the history panel.
If the new-history is missing:
Click on the galaxy-gear icon (History options) on the top of the history panel
Select the option Create New from the menu
Import the ChIP-seq raw data (*.fastqsanger) from Zenodo.
Copy the link location
Open the Galaxy Upload Manager (galaxy-upload on the top-right of the tool panel)
Select Paste/Fetch Data
Paste the link into the text field
Press Start
Close the window
Examine the data in a FASTQ file by clicking on the galaxy-eye (eye) icon.
Question
What are four key features of a FASTQ file?
What is the main difference between a FASTQ and a FASTA file?
A FASTQ file contains a sequence identifier and additional information, the raw sequence, information about the sequence again with optional information, and quality information about the sequence.
A FASTA file contains only the description of the sequence and the sequence itself. A FASTA file does not contain any quality information.
FastQCTool: toolshed.g2.bx.psu.edu/repos/devteam/fastqc/fastqc/0.72+galaxy1 : Run FastQC on each FASTQ file to assess the quality of the raw data. An explanation of the results can be found on the FastQC web page.
param-files“Short read data from your current history”: The uploaded fastqsanger files.
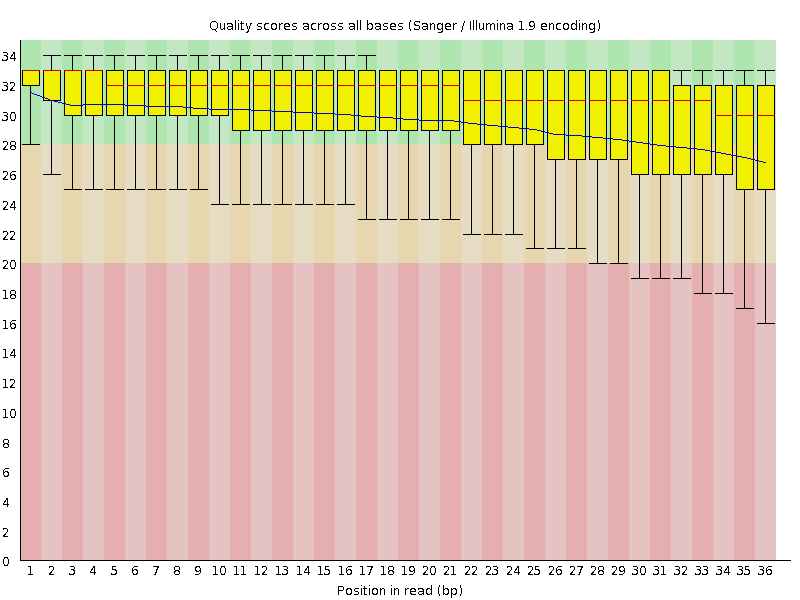
Figure 1: Sequence quality per base generated by FastQC before end trimming.
Question
What does the y-axis represent in Figure 3?
Why is the quality score decreasing across the length of the reads?
The phred-score. This score gives the probability of an incorrect base e.g. a score of 20 means that it is likely by 1% that one base is incorrect. See here for more information.
This is an unsolved technical issue of the sequencing machines. The longer the sequences are the more likely are errors. See here for more information.
Trimming and clipping reads
It is often necessary to trim a sequenced read to remove bases sequenced with high uncertainty (i.e. low-quality bases). In addition, artificial adaptor sequences used in library preparation protocols need to be removed before attempting to align the reads to a reference genome.
Hands-on: Trimming and clipping reads
TrimmomaticTool: toolshed.g2.bx.psu.edu/repos/pjbriggs/trimmomatic/trimmomatic/0.38.0 : Run Trimmomatic to trim low-quality reads.
“Single-end or paired-end reads?”: Single-end
param-files“Input FASTQ file”: Select all of the FASTQ files
“Perform initial ILLUMINACLIP?”: No
“Select Trimmomatic operation to perform”: Sliding window trimming (SLIDINGWINDOW)
“Number of bases to average across”: 4
“Average quality required”: 20
If the FASTQ files cannot be selected, check whether their format is FASTQ with Sanger-scaled quality values (fastqsanger). If not, you can edit the data type by clicking on the pencil symbol next to a file in the history, clicking the “Datatype” tab, and choosing fastqsanger as the “New Type”.
FastQCTool: toolshed.g2.bx.psu.edu/repos/devteam/fastqc/fastqc/0.72+galaxy1 : Rerun FastQC on each trimmed/clipped FASTQ file to determine whether low-quality and adaptor sequences were correctly removed.
param-files“Short read data from your current history”: The output of Trimmomatic.
Question
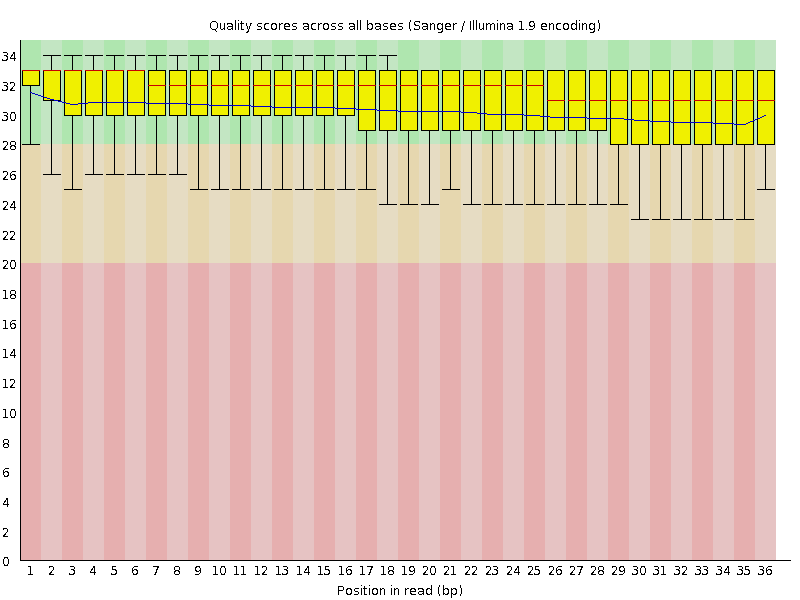
How did the range of read lengths change after trimming/clipping?
Before trimming, all the reads were the same length, which reflected the number of rounds of nucleotide incorporation in the sequencing experiment. After trimming, read lengths span a range of values reflecting different lengths of the actual DNA fragments captured during the ChIP experiement.
Figure 2: Sequence quality per base generated by FastQC after end trimming.
Aligning reads to a reference genome
To determine where DNA fragments originated from in the genome, the sequenced reads must be aligned to a reference genome. This is equivalent to solving a jigsaw puzzle, but unfortunately, not all pieces are unique. In principle, you could do a BLAST analysis to figure out where the sequenced pieces fit best in the known genome. Aligning millions of short sequences this way, however, can take a couple of weeks.
Nowadays, there are many read alignment programs for sequenced DNA, BWA being one of them. You can read more about the BWA algorithm and tool here.
Hands-on: Aligning reads to a reference genome
BWATool: toolshed.g2.bx.psu.edu/repos/devteam/bwa/bwa/0.7.17.4 : Run BWA to map the trimmed/clipped reads to the mouse genome.
“Will you select a reference genome…“: Use a built-in genome index
param-files“Select fastq dataset”: Select all of the trimmed FASTQ files
Rename files to reflect the origin and contents.
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, change the Name field
Click the Save button
Inspect a file produced by BWA.
Question
What datatype is the BWA output file?
How many reads were mapped from each file?
The output is a BAM file.
Check the number of lines for each file in your history. This gives you a rough estimate.
Samtools idxstatsTool: toolshed.g2.bx.psu.edu/repos/devteam/samtools_idxstats/samtools_idxstats/2.0.3 : Run idxstats to get statistics of the BWA alignments.
param-files“BAM file”: Select all of the mapped BAM files
Examine the output (galaxy-eye)
Question
What does each column in the output represent (Tip: look at the Tool Form)?
How many reads were mapped to chromosome 19 in each experiment?
If the mouse genome has 21 pairs of chromosomes, what are the other reference chromosomes (e.g. chr1_GL456210_random)?
Column 1: Reference sequence identifier
Column 2: Reference sequence length
Column 3: Number of mapped reads
Column 4: Number of placed but unmapped reads (typically unmapped partners of mapped reads)
This information can be seen in column 3, e.g. for Megakaryocyte_Tal1_R1 2143352 reads are mapped. Your answer might be slightly different if different references or tool versions are used.
Some of these other reference sequences are parts of chromosomes but it is unclear where exactly, e.g. chr1_GL456210_random is a part of chromosome 1. There are entries like chrUn that are not associated with a chromosome but it is believed that they are part of the genome.
Assessing correlation between samples
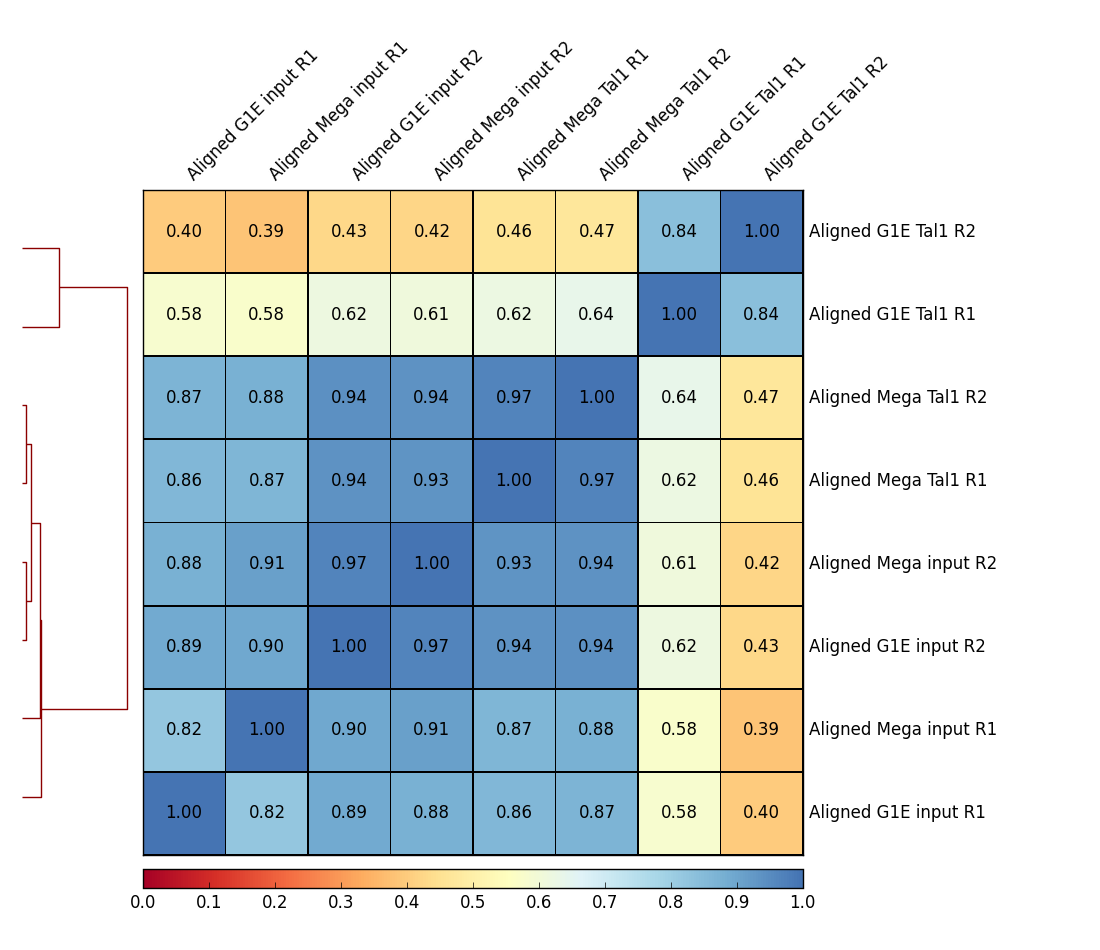
To assess the similarity between the replicates sequencing datasets, it is a common technique to calculate the correlation of read counts for the different samples.
We expect that the replicate samples will cluster more closely to each other than to other samples. We will be use tools from the package deepTools for the next few steps. More information on deepTools can be found here.
Hands-on: Assessing correlation between samples
multiBamSummary splits the reference genome into bins of equal size and counts the number of reads in each bin from each sample. We set a small bin size here because we are working with a subset of reads that align to only a fraction of the genome.
multiBamSummaryTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_multi_bam_summary/deeptools_multi_bam_summary/3.3.2.0.0 : Run multiBamSummary to get read coverage of the alignments.
“Sample order matters”: No
param-files“Bam files”: Select all of the aligned BAM files
“Bin size in bp”: 1000
plotCorrelationTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_plot_correlation/deeptools_plot_correlation/3.3.2.0.0 : Run plotCorrelation to visualize the results.
“Matrix file from the multiBamSummary tool”: Select the multiBamSummary output file
“Correlation method”: Pearson
“Plotting type”: Heatmap
“Plot the correlation value”: Yes
“Skip zeros”: Yes
“Remove regions with very large counts”: Yes
Feel free to play around with these parameter settings!
Question
Why do we want to skip zeros in plotCorrelation?
What happens if the Spearman’s correlation method is used instead of the Pearson method?
What does the output of making a Scatterplot instead of a Heatmap look like?
Large areas of zeros would lead to a correlation of these areas. The information we would get out of this computation would be meaningless.
Figure 3: Heatmap of correlation matrix generated by plotCorrelation.
Additional information on how to interpret plotCorrelation plots can be found here.
Assessing IP strength
We will now evaluate the quality of the immunoprecipitation step in the ChIP-seq protocol.
Hands-on: Assessing IP strength
plotFingerprintTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_plot_fingerprint/deeptools_plot_fingerprint/3.3.2.0.0 : Run plotFingerprint to assess ChIP signal strength.
param-files“Bam files”: Select all of the aligned BAM files for the G1E cell type
“Show advanced options”: yes
“Bin size in bases”: 100
“Skip zeros”: Yes
Rerun plotFingerprint for the Megakaryocyte cell type.
View the output images.
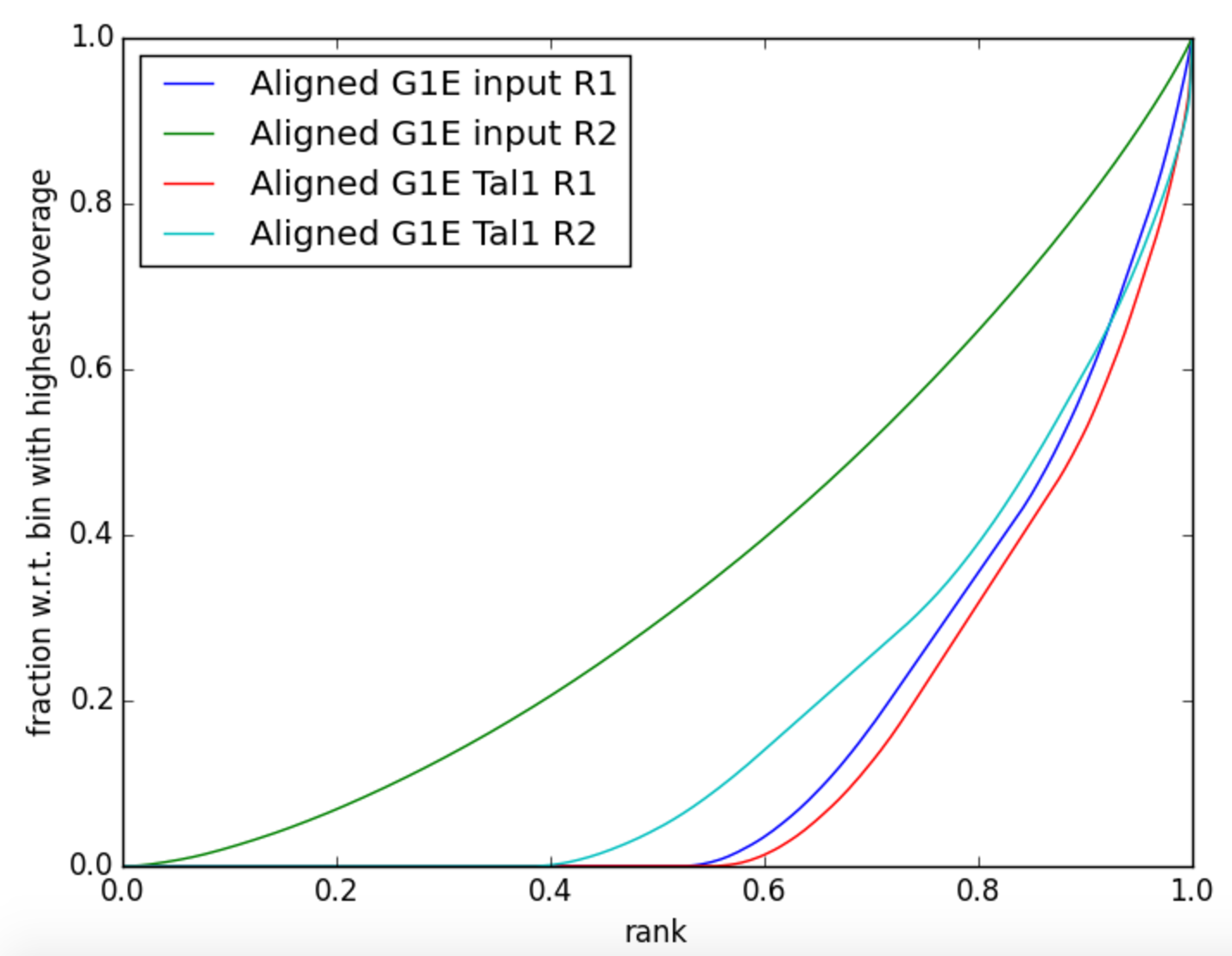
Figure 4: Strength of immunoprecipitation of TAL1.
Question
What does this graph in Figure 10 represent?
How do (or should) input datasets differ from IP datasets?
What do you think about the quality of the IP for this experiment?
How does the quality of the IP for megakaryocytes compare to G1E cells?
It shows us how good the ChIP Signal compared to the control signal is. An ideal control (input) with perfect uniform distribution of reads along the genome (i.e. without enrichment in open chromatin etc.) and infinite sequencing coverage should generate a straight diagonal line. A very specific and strong ChIP enrichment will be indicated by a prominent and steep rise of the cumulative sum towards the highest rank.
We expect that the control (input) signal is more or less uniform distributed over the genome (e.g. like the green line in the image above). The IP dataset should look more like the red line but it would be better if the values for IP start to increase at around 0.8 on the x-axis.
The enrichment did not work as it should. Compare the blue line with the red one! For your future experiments: You can never have enough replicates!
The quality of megakaryocytes is better then G1E.
Additional information on how to interpret plotFingerprint plots can be found here.
Determining TAL1 binding sites
Now that BWA has aligned the reads to the genome, we will use the tool MACS2 to identify regions of TAL1 occupancy, which are called “peaks”. Peaks are determined from pileups of sequenced reads across the genome that correspond to where TAL1 binds.
MACS2 will perform two tasks:
Identify regions of TAL1 occupancy (peaks).
Generate bedGraph files for visual inspection of the data on a genome browser.
MACS2 callpeakTool: toolshed.g2.bx.psu.edu/repos/iuc/macs2/macs2_callpeak/2.1.1.20160309.6 : Run MACS2 callpeak with the aligned read files from the previous step as Treatment (TAL1) and Control (input).
“Are you pooling Treatment Files?”: Yes
param-files“ChIP-Seq Treatment File”: Select all of the replicate ChIP-Seq treatment aligned BAM files for one cell type
“Do you have a Control File?”: Yes
“Are you pooling Control Files?”: Yes
param-files“ChIP-Seq Control File”: Select replicate ChIP-Seq control aligned BAM files for the same cell type
“Format of Input Files”: Single-end BAM
“Effective genome size”: M. musculus
“Additional Outputs”: Select Peaks as tabular file (compatible wih MultiQC), Peak summits, Scores in bedGraph files (--bdg)
Rename files to reflect the origin and contents.
Repeat for the other cell type.
Inspection of peaks and aligned data
It is critical to visualize NGS data on a genome browser after alignment to evaluate the “goodness” of the analysis. Evaluation criteria will differ for various NGS experiment types, but for ChIP-seq data we want to ensure reads from a Treatment/IP sample are enriched at peaks and do not localize non-specifically (like the control/input condition).
MACS2 generates bedGraph and BED files that we will use to visualize read abundance and peaks, respectively, at regions MACS2 determines to be TAL1 peaks using Galaxy’s in-house genome browser, Trackster.
Inspection of peaks and aligned data with Trackster
We will import a gene annotation file so we can visualize aligned reads and TAL1 peaks relative to gene features and positions.
Hands-on: Inspecting peaks and aligned data with Trackster
Import gene annotations file from Zenodo
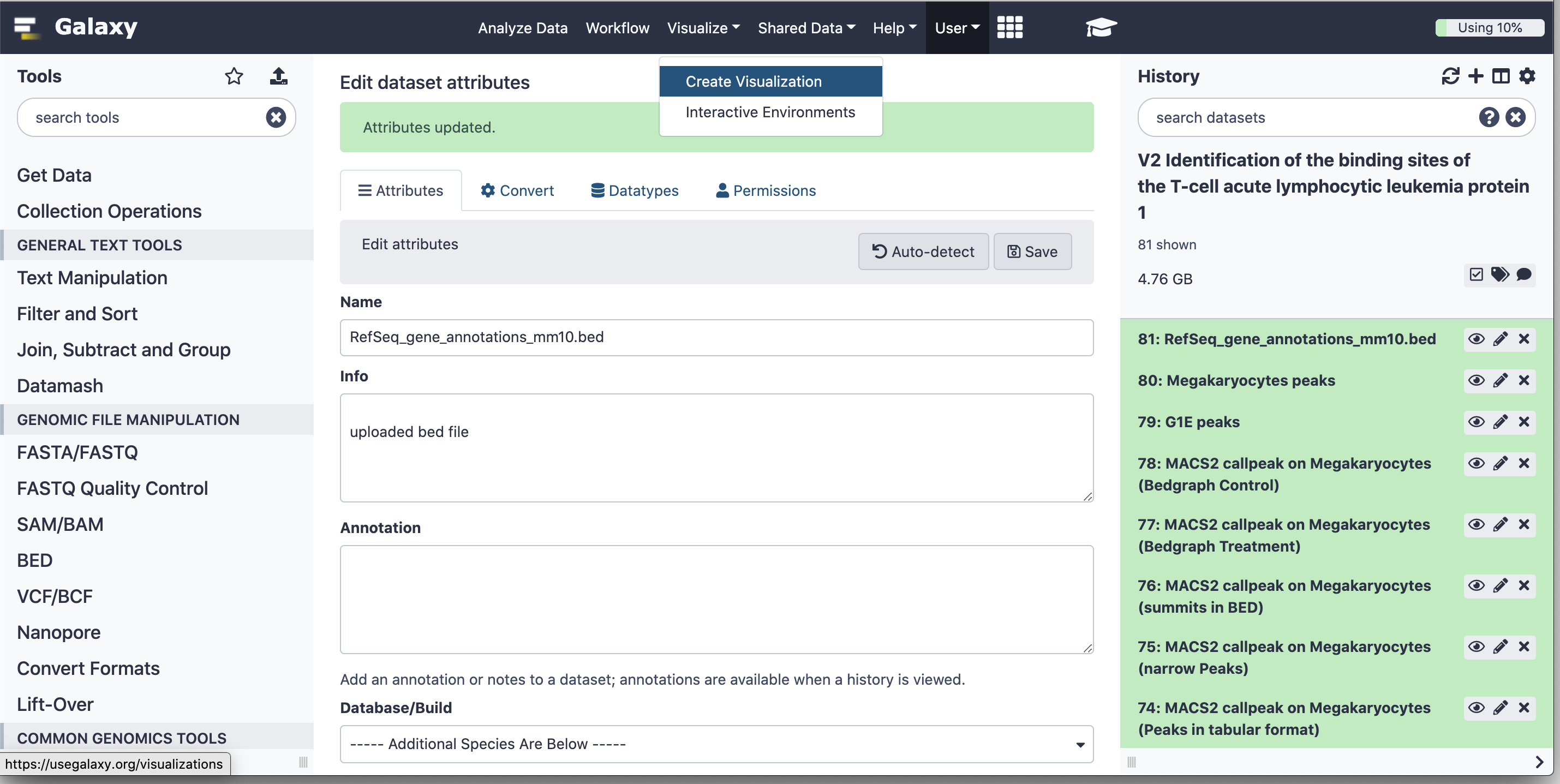
Click “Visualize” on the page header and select “Create Visualization”
Figure 5: Trackster can be accessed from the Visualize button at the top of the screen.
Set up Trackster
Select Trackster
“Select a dataset to visualize”: Select the imported gene annotation file (Tip: if this file doesn’t appear as an option, go back to the history and edit the attribute Database/Build to be mm10)
Click “Create Visualization”
Configure the visualization
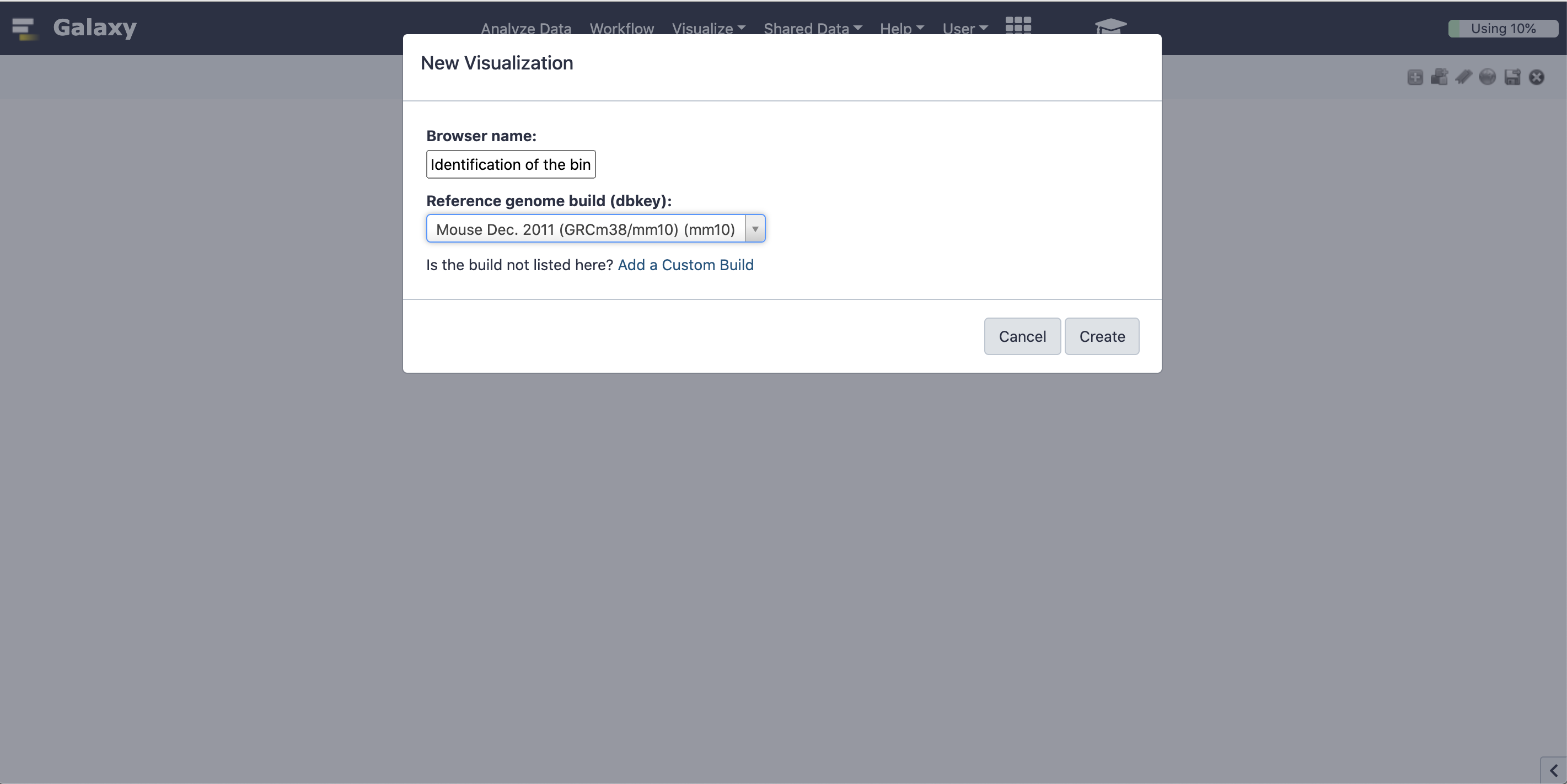
Select “View in new visualization”
“Browser name”: Enter a name for your visualization
“Reference genome build (dbkey):”: mm10
Click “Create”
Figure 6: Assign session name and reference genome.
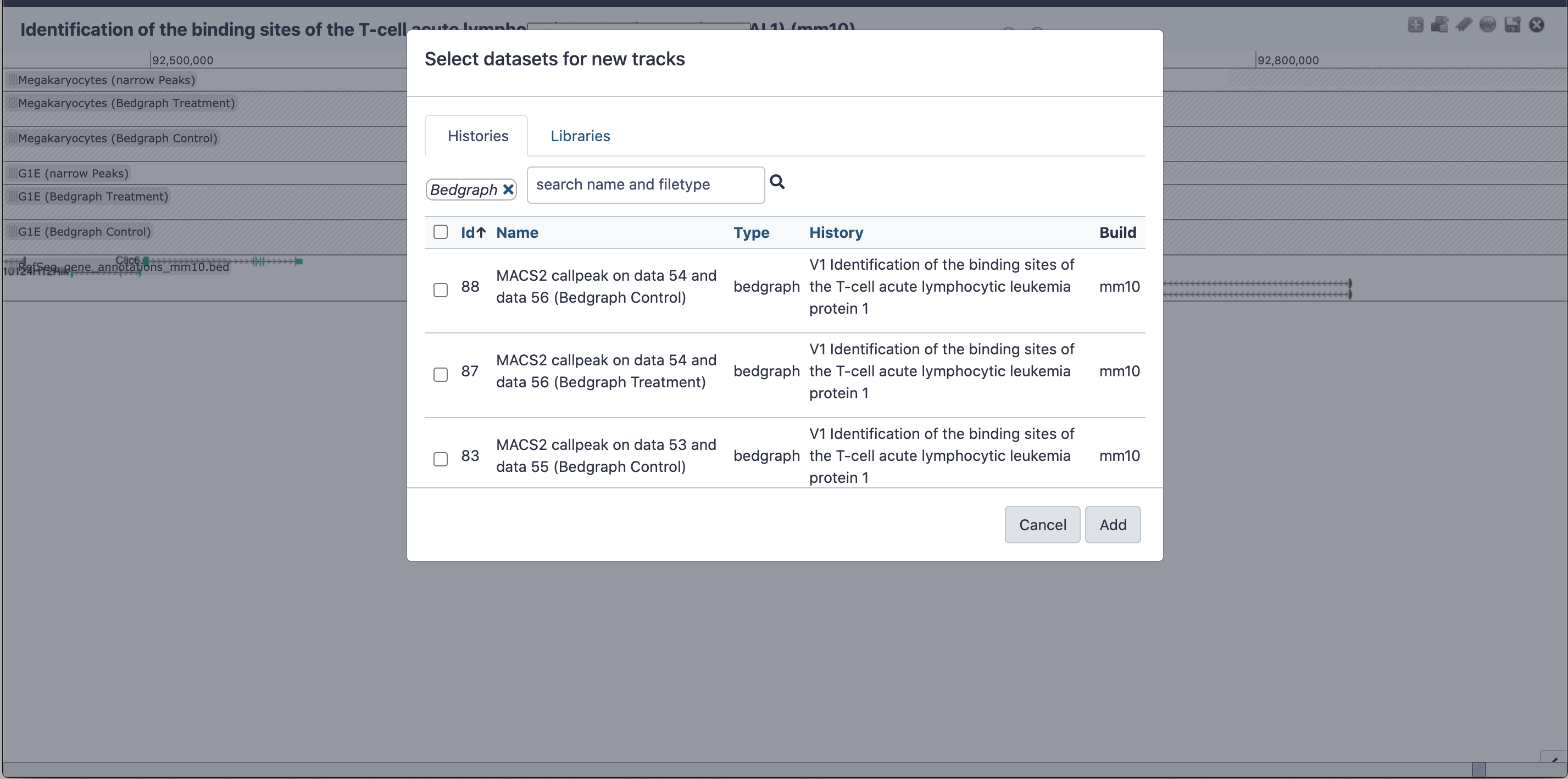
Add tracks to Trackster
Click the “Add tracks” (plus sign) button at the top right
Using the search bar, search for and add the following tracks from MACS2 callpeak output to your view
G1E Treatment bedGraph
G1E Control bedGraph
G1E narrow peaks
Megakaryocytes Treatment bedGraph
Megakaryocytes Control bedGraph
Megakaryocytes narrow peaks
Rename the tracks, if desired
Play around with the track configurations, for example the color or the display mode
Figure 7: Select data from the history to view in Trackster.
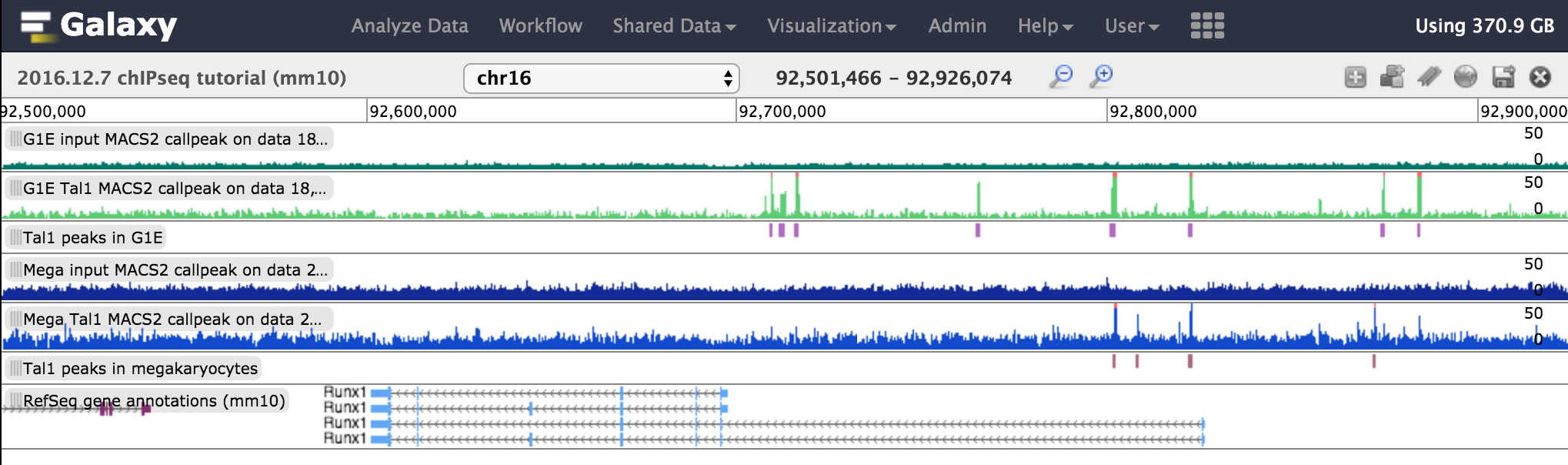
Navigate to the Runx1 locus (chr16:92501466-92926074) to inspect the aligned reads and TAL1 peaks.
Question
What do you see at the Runx1 locus in Trackster?
Directly upstream of the shorter Runx1 gene models is a cluster of 3 TAL1 peaks that only appear in the G1E cell type, but not in Megakaryocytes. Further upstream, there are some shared TAL1 peaks in both cell types.
Figure 8: The Runx1 locus with TAL1 peaks identified.
Identifying unique and common TAL1 peaks between stages
We have processed ChIP-seq data from two stages of hematopoiesis and have lists of TAL1-occupied sites (peaks) in both cellular states. The next analysis step is to identify TAL1 peaks that are shared between the two cellular states and peaks that are specific to either cellular state.
Hands-on: Identifying unique and common TAL1 peaks between states
bedtools Intersect intervalsTool: toolshed.g2.bx.psu.edu/repos/iuc/bedtools/bedtools_intersectbed/2.29.0 : Run bedtools Intersect intervals to find peaks that exist both in G1E and megakaryocytes.
param-file“File A to intersect with B”: Select the TAL1 G1E narrow peaks BED file
param-file“File B to intersect with A”: Select the TAL1 Megakaryocytes narrow peaks BED file
Running this tool with the default settings will return overlapping peaks of both files.
bedtools Intersect intervalsTool: toolshed.g2.bx.psu.edu/repos/iuc/bedtools/bedtools_intersectbed/2.29.0 : Run bedtools Intersect intervals to find peaks that exist only in G1E.
param-file“File A to intersect with B”: Select the TAL1 G1E narrow peaks BED file
param-file“File B to intersect with A”: Select the TAL1 Megakaryocytes narrow peaks BED file
“Report only those alignments that **do not** overlap the BED file”: Yes
bedtools Intersect intervalsTool: toolshed.g2.bx.psu.edu/repos/iuc/bedtools/bedtools_intersectbed/2.29.0 : Run bedtools Intersect intervals to find peaks that exist only in megakaryocytes.
param-file“File A to intersect with B”: Select the TAL1 Megakaryocytes narrow peaks BED file
param-file“File B to intersect with A”: Select the TAL1 G1E narrow peaks BED file
“Report only those alignments that **do not** overlap the BED file”: Yes
Rename files to reflect the origin and contents.
Question
How many TAL1 peaks are common to both G1E cells and megakaryocytes?
How many are unique to G1E cells?
How many are unique to megakaryocytes?
1 peak (answer may vary depending on references and tool versions used)
407 peaks (answer may vary depending on references and tool versions used)
139 peaks (answer may vary depending on references and tool versions used)
Generating Input normalized coverage files
We will generate Input normalized coverage (bigWig) files for the ChIP samples, using the bamCompare tool from deepTools2. bamCompare provides multiple options to compare the two files (e.g. log2ratio, subtraction). We will use log2 ratio of the ChIP samples over Input.
Hands-on: Generating input-normalized bigwigs
bamCompareTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_bam_compare/deeptools_bam_compare/3.3.2.0.0 : Run bamCompare to get the log2 read ratios between treatment and control samples.
“First BAM/CRAM file (e.g.* treated sample)”*: Select the Megakaryocyte TAL1 aligned BAM file for replicate 1 (R1)
“Second BAM/CRAM file (e.g.* control sample)”*: Select the Megakaryocyte input aligned BAM file for replicate 1 (R1)
“How to compare the two files”: Compute log2 of the number of reads
Repeat this step for all treatment and control samples:
Plotting your region of interest will involve using two tools from the deepTools suite:
computeMatrix: Computes the signal on given regions, using the bigwig coverage files from different samples.
plotHeatmap: Plots heatMap of the signals using the computeMatrix output.
Optionally, you can use plotProfile to create a profile plot using to computeMatrix output.
Hands-on: Calculating signal matrix on MACS2 output
computeMatrixTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_compute_matrix/deeptools_compute_matrix/3.3.2.0.0 : Run computeMatrix to prepare data for plotting a heatmap of TAL1 peaks.
param-fileSelect Regions > “Regions to plot”: Select the MACS2 narrow peaks files for G1E cells (TAL1 over Input)
param-file“Score file”: Select the bigWig files for the G1E cells (log2 ratios from bamCompare)
“computeMatrix has two main output options”: reference-point
“The Reference point for plotting”: center of region
“Distance upstream of the start site of the regions defined in the region file”: 5000
“Distance downstream of the end site of the given regions”: 5000
“Show advanced options”: Yes
“Convert missing values ot zero”: Yes
“Skip zeros”: Yes
Repeat for Megakaryoctes.
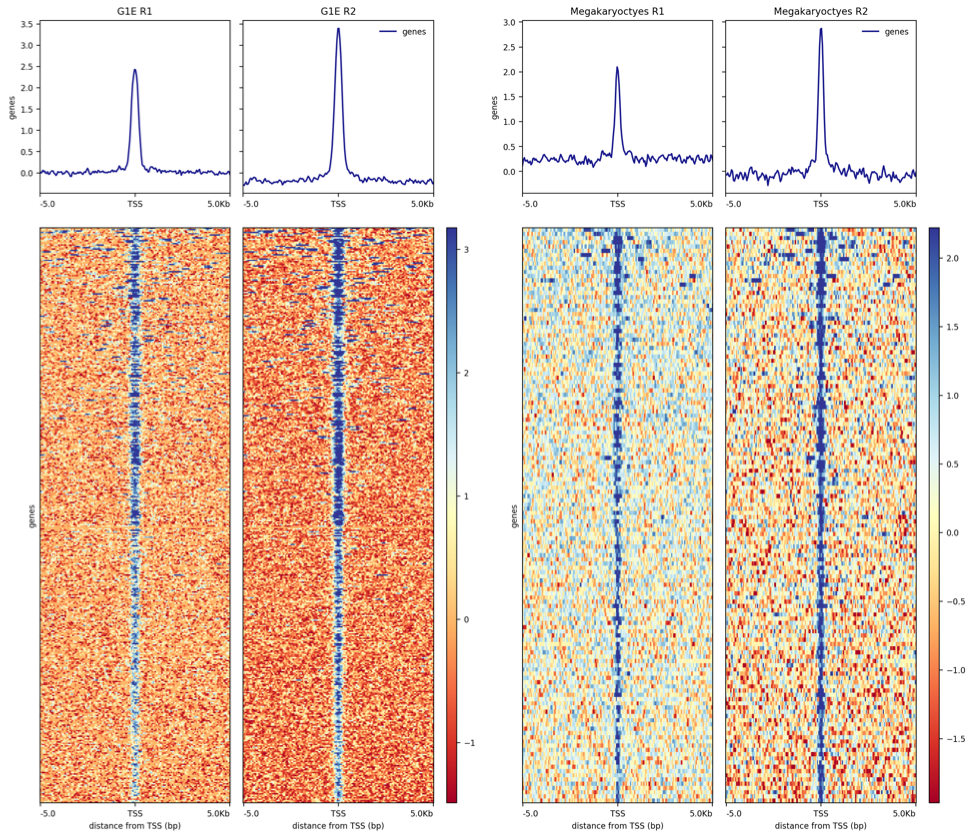
Hands-on: Plotting a heatmap of TAL1 peaks
plotHeatmapTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_plot_heatmap/deeptools_plot_heatmap/3.3.2.0.1 : Run plotHeatmap to create a heatmap for score distributions across TAL1 peak genomic regions in each cell type.
“Matrix file from the computeMatrix tool”: Select the computeMatrix output for G1E cells
“Show advanced options”: Yes
“Labels for the samples (each bigwig) plotted”: Enter sample labels in the order you added them in computeMatrix, separated by spaces.
Repeat for Megakaryocytes.
The outputs should look similar to this:
Additional optional analyses
Assessing GC bias
A common problem of PCR-based protocols is the observation that GC-rich regions tend to be amplified more readily than GC-poor regions.
We will now check whether the samples have more reads from regions of the genome with high GC.
Hands-on: Assessing GC bias
computeGCbiasTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_compute_gc_bias/deeptools_compute_gc_bias/3.3.2.0.0 : Run computeGCbias to determine the GC bias of the sequenced reads.
param-file“Bam file”: Select an aligned BAM file
“Reference genome”: locally cached
“Using reference genome”: mm10
“Effective genome size”: user specified
“Effective genome size”: 10000000
“Fragment length used for the sequencing”: 50
Question
Why would we worry more about checking for GC bias in an input file?
Does this dataset have a GC bias?
In an input ChIP-seq file, the expectation is that DNA fragments are uniformly sampled from the genome. This is in contrast to an IP ChIP-seq file where it is expected that certain genomic regions contain more reads (i.e. regions that are bound by the protein that is immunopurified). Therefore, non-uniformity of reads in the input sample could be a result of GC-bias, whereby more GC-rich fragments are preferentially amplified during PCR.
To answer this question, run the computeGCbias tool as described above and check out the results. What do YOU think? For more examples and information on how to interpret the results, check out the tool usage documentation here.
correctGCbiasTool: toolshed.g2.bx.psu.edu/repos/bgruening/deeptools_correct_gc_bias/deeptools_correct_gc_bias/3.3.2.0.0 : Run correctGCbias to generate GC-corrected BAM/CRAM files.
Question
What does the tool correctGCbias do?
What is the output of this tool?
What are some caveats to be aware of if using the output of this tool in downstream analyses?
The correctGCbias tool removes reads from regions with higher coverage than expected (typically corresponding to GC-rich regions) and adds reads to regions with lower coverage than expected (typically corresponding to AT-rich regions).
The output of this tool is a GC-corrected file in BAM, bigWig, or bedGraph format.
The GC-corrected output file likely contains duplicated reads in low-coverage regions where reads were added to match the expected read density. Therefore, it is necessary to avoid filtering or removing duplicate reads in any downstream analyses.
Additional information on how to interpret computeGCbias plots can be found here.
Conclusion
In this exercise you imported raw Illumina sequencing data, evaluated the quality before and after you trimmed reads with low confidence scores, aligned the trimmed reads, identified TAL1 peaks relative to the negative control (background), and visualized the aligned reads and TAL1 peaks relative to gene structures and positions. Additional, you assessed the “goodness” of the experiments by looking at metrics such as GC bias and IP enrichment.
Key points
Sophisticated analysis of ChIP-seq data is possible using tools hosted by Galaxy.
Genomic dataset analyses require multiple methods of quality assessment to ensure that the data are appropriate for answering the biology question of interest.
By using the sharable and transparent Galaxy platform, data analyses can easily be shared and reproduced.
Zhang, Y., T. Liu, C. A. Meyer, J. Eeckhoute, D. S. Johnson et al., 2008 Model-based Analysis of ChIP-Seq (MACS). Genome Biology 9: R137. 10.1186/gb-2008-9-9-r137
Wu, W., C. S. Morrissey, C. A. Keller, T. Mishra, M. Pimkin et al., 2014 Dynamic shifts in occupancy by TAL1 are guided by GATA factors and drive large-scale reprogramming of gene expression during hematopoiesis. Genome Research 24: 1945–1962. 10.1101/gr.164830.113
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{epigenetics-tal1-binding-site-identification,
author = "Mallory Freeberg and Mo Heydarian and Vivek Bhardwaj and Joachim Wolff and Anika Erxleben",
title = "Identification of the binding sites of the T-cell acute lymphocytic leukemia protein 1 (TAL1) (Galaxy Training Materials)",
year = "2022",
month = "10",
day = "18"
url = "\url{https://training.galaxyproject.org/training-material/topics/epigenetics/tutorials/tal1-binding-site-identification/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Batut_2018,
doi = {10.1016/j.cels.2018.05.012},
url = {https://doi.org/10.1016%2Fj.cels.2018.05.012},
year = 2018,
month = {jun},
publisher = {Elsevier {BV}},
volume = {6},
number = {6},
pages = {752--758.e1},
author = {B{\'{e}}r{\'{e}}nice Batut and Saskia Hiltemann and Andrea Bagnacani and Dannon Baker and Vivek Bhardwaj and Clemens Blank and Anthony Bretaudeau and Loraine Brillet-Gu{\'{e}}guen and Martin {\v{C}}ech and John Chilton and Dave Clements and Olivia Doppelt-Azeroual and Anika Erxleben and Mallory Ann Freeberg and Simon Gladman and Youri Hoogstrate and Hans-Rudolf Hotz and Torsten Houwaart and Pratik Jagtap and Delphine Larivi{\`{e}}re and Gildas Le Corguill{\'{e}} and Thomas Manke and Fabien Mareuil and Fidel Ram{\'{\i}}rez and Devon Ryan and Florian Christoph Sigloch and Nicola Soranzo and Joachim Wolff and Pavankumar Videm and Markus Wolfien and Aisanjiang Wubuli and Dilmurat Yusuf and James Taylor and Rolf Backofen and Anton Nekrutenko and Björn Grüning},
title = {Community-Driven Data Analysis Training for Biology},
journal = {Cell Systems}
}
Congratulations on successfully completing this tutorial!
 Mallory Freeberg
Mallory Freeberg Mo Heydarian
Mo Heydarian Vivek Bhardwaj
Vivek Bhardwaj Joachim Wolff
Joachim Wolff
 Anika Erxleben
Anika Erxleben Questions:
Questions: