Trio Analysis using Synthetic Datasets from RD-Connect GPAP
 Jasper Ouwerkerk
Jasper Ouwerkerk Wolfgang Maier
Wolfgang Maier
 Helena Rasche
Helena Rasche Saskia Hiltemann
Saskia HiltemannOverviewQuestions:Objectives:
How do you import data from the EGA?
How to download files with HTSGET in Galaxy?
How do you pre-process VCFs?
How do you identify causative variants?
Requirements:
Requesting DAC access and importing data from the EGA.
Pre-process VCFs using regular expressions.
Use annotations and phenotype information to find the causative variant(s).
- Introduction to Galaxy Analyses
- Sequence analysis
- Quality Control: slides slides - tutorial hands-on
- Mapping: slides slides - tutorial hands-on
Time estimation: 2 hoursSupporting Materials:Last modification: Oct 18, 2022
 Questions:
Questions:
Introduction
To discover causal mutations of inherited diseases it’s common practice to do a trio analysis. In a trio analysis DNA is sequenced of both the patient and parents. Using this method, it’s possible to identify multiple inheritance patterns. Some examples of these patterns are autosomal recessive, autosomal dominant, and de-novo variants, which are represented in the figure below. To elaborate, the most left tree shows an autosomal dominant inhertitance pattern where the offspring inherits a faulty copy of the gene from one of the parents. The center subfigure represents an autosomal recessive disease, here the offspring inherited a faulty copy of the same gene from both parents. In the right subfigure a de-novo mutation is shown, which is caused by a mutation during the offspring’s lifetime.

To discover these mutations either whole exome sequencing (WES) or whole genome sequencing (WGS) can be used. With these technologies it is possible to uncover the DNA of the parents and offspring to find (shared) mutations in the DNA. These mutations can include insertions/deletions (indels), loss of heterozygosity (LOH), single nucleotide variants (SNVs), copy number variations (CNVs), and fusion genes.
In this tutorial we will also make use of the HTSGET protocol, which is a program to download our data securely and savely. This protocol has been implemented in the EGA Download Client Tool: toolshed.g2.bx.psu.edu/repos/iuc/ega_download_client/pyega3/4.0.0+galaxy0 tool, so we don’t have to leave Galaxy to retrieve our data.
We will not start our analysis from scratch, since the main goal of this tutorial is to use the HTSGET protocol to download variant information from an online archive and to find the causative variant from those variants. If you want to learn how to do the analysis from scratch, using the raw reads, you can have a look at the Exome sequencing data analysis for diagnosing a genetic disease tutorial.
Agenda:In this tutorial, we will cover:
Data preperation
In this tutorial we will use case 5 from the RD-Connect GPAP synthetic datasets. The dataset that we will use consists of WGS VCFs from a real healthy family trio, which originates from the Illumina Platinum initiative Eberle et al. 2017 and was made available by the HapMap project. In our dataset a real causative variant was manually spiked-in that should cause breast cancer. The spike-in has been synthetically introduced in the mother and daughter. Here our goal is to identify the genetic variation that is responsible for the disease.
We offer two ways to download the files. Firstly, you can download the files directly from the EGA-archive by requesting DAC access. This will take only 1 workday and gives you access to all of the RD-Connect GPAP synthetic datasets. However if you don’t have the time you can also download the data from zenodo.
hands_on Hands-on: Choose Your Own Tutorial
This is a "Choose Your Own Tutorial" section, where you can select between multiple paths. Click one of the buttons below to select how you want to follow the tutorial
Here you can choose to either follow the data preperation for the data from the EGA-archive or Zenodo.
I see, you can’t wait to get DAC access. To download the data from zenodo for this tutorial you can follow the step below.
Hands-on: Retrieve data from zenodo
- Import the 3 VCFs from Zenodo to Galaxy as a collection.
https://zenodo.org/record/6483454/files/Case5_F.17.g.vcf.gz https://zenodo.org/record/6483454/files/Case5_IC.17.g.vcf.gz https://zenodo.org/record/6483454/files/Case5_M.17.g.vcf.gz
- Copy the link location
Open the Galaxy Upload Manager (galaxy-upload on the top-right of the tool panel)
Click on Collection on the top
- Select Paste/Fetch Data
Paste the link into the text field
Press Start
Click on Build when available
Enter a name for the collection
- Click on Create list (and wait a bit)
Set the datatype to vcf.
Click on Start
If you forgot to select the “Collections” tab during upload, please put the file in a collection now.
- Click on Operations on multiple datasets (check box icon) at the top of the history panel
- Check all the datasets in your history you would like to include
Click For all selected.. and choose Build dataset list
- Enter a name for your collection
- Click Create List to build your collection
- Click on the checkmark icon at the top of your history again
Getting DAC access
Our test data is stored in EGA, which can be easily accessed using the EGA Download Client. Our specific EGA dataset accession ID is: “EGAD00001008392”. However, before you can access this data you need to request DAC access to this dataset. This can be requested by emailing to helpdesk@ega-archive.org, don’t forget to mention the dataset ID! When the EGA grants you access it will create an account for you, if you don’t have it already. Next, you should link your account to your Galaxy account by going to the homepage on Galaxy and at the top bar click User > Preferences > Manage Information. Now add your email and password of your (new) EGA account under: Your EGA (european Genome Archive) account. After that you can check if you can log in and see if you have access to the dataset.
- EGA Download Client Tool: toolshed.g2.bx.psu.edu/repos/iuc/ega_download_client/pyega3/4.0.0+galaxy0 with the following parameters:
- “What would you like to do?”:
List my authorized datasetsComment: Check if the dataset is listed.Check if your dataset is listed in the output of the tool. If not you can look at the header of the output to find out why it is not listed. When the header does not provide any information you could have a look at the error message by clicking on the eye galaxy-eye of the output dataset and then click on the icon view details details. The error should be listed at Tool Standard Error.
Download list of files
When you have access to the EGA dataset, you can download all the needed files. However, the EGA dataset contains many different filetypes and cases, but we are only interested in the VCFs from case 5 and, to reduce execution time, the variants on chromosome 17. To be able to donwload these files we first need to request the list of files from which we can download. Make sure to use version 4+ of the EGA Download Client Tool: toolshed.g2.bx.psu.edu/repos/iuc/ega_download_client/pyega3/4.0.0+galaxy0 .
Hands-on: Request list of files in the dataset
- EGA Download Client Tool: toolshed.g2.bx.psu.edu/repos/iuc/ega_download_client/pyega3/4.0.0+galaxy0 version 4+ with the following parameters:
- “What would you like to do?”:
List files in a datasets- “EGA Dataset Accession ID?”:
EGAD00001008392Tools are frequently updated to new versions. Your Galaxy may have multiple versions of the same tool available. By default, you will be shown the latest version of the tool.
Switching to a different version of a tool:
- Open the tool
- Click on the tool-versions versions logo at the top right
- Select the desired version from the dropdown list
Filter list of files
Now that we have listed all the files, we need to filter out the files we actually need. We can do this by using a simple regular expression or regex. With regex it will be easy to find or replace patterns within a textfile.
Hands-on: Filter out VCFs from list of files
- Search in textfiles Tool: toolshed.g2.bx.psu.edu/repos/bgruening/text_processing/tp_grep_tool/1.1.1 with the following parameters:
- param-file “Select lines from”:
List of EGA datasets(output of EGA Download Client tool)- “Type of regex”:
Extended (egrep)- “Regular Expression”:
Case5.+17.+vcf.gz$The regex might seem a bit complicated if you never worked with it, however it is quite simple. We simply search for lines which contain our sequence of characters, which are lines that contain Case5 then any character for any length, denoted by the “.+”, until (chromosome) 17 is found and then again any character for any length until the sequence ends with, denoted by the dollar sign, “vcf.gz”.- “Match type”:
case sensitive
Download files
After the filtering you should have a tabular file with 3 lines each containing the ID of a VCF file from case 5, as shown below.
EGAF00005573839 1 33859685 53277d993a780e0c295079bf1346ee9f Case5_IC.17.g.vcf.gz
EGAF00005573866 1 33350163 7e612852ee0824be458fbf9aeecaa61a Case5_M.17.g.vcf.gz
EGAF00005573882 1 42856357 14b53924d1492e28ad6078ceb8cfdbc7 Case5_F.17.g.vcf.gz
Hands-on: Download listed VCFs
- EGA Download Client Tool: toolshed.g2.bx.psu.edu/repos/iuc/ega_download_client/pyega3/4.0.0+galaxy0 with the following parameters:
- “What would you like to do?”:
Download multiple files (based on a file with IDs)
- param-file “Table with IDs to download”:
Filtered list of files(output of Search in textfiles tool)- “Column containing the file IDs”:
Column: 1After the download you should have a collection with one file for each family member, i.e. mother (M), father (F), and case (IC). Make sure the files are recognized as the vcf_bgzip format.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click on the galaxy-chart-select-data Datatypes tab on the top
- Select
datatypes
- tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
Decompress VCFs
Finally, we need to decompress our bgzipped VCFs, since we will use a text manipulation tool as a next step to process the VCFs. To decompress the vcf we will use a built-in tool from Galaxy, which can be accessed by manipulating the file itself in a similair fashion as changing its detected type.
Hands-on: Convert compressed vcf to uncompressed.Open the collection of VCFs and execute the following steps for each VCF.
Click on the pencil galaxy-pencil of the vcf you want to convert.
Click on the convert tab galaxy-gear.
Under Target datatype select
vcf (using 'Convert compressed file to uncompressed.')Click exchange Create Dataset.
After transforming all the VCFs you need to combine the converted VCFs into a colllection again.
- Click on the dataset selector icon param-check in your history.
- Select the 3 vcf files.
- Click on the button For all selected… and select Build Dataset List
- Give the new collection a name and click on Create collection.
Pre-Processing
Before starting the analysis, the VCF files have to be pre-processed in order to meet input requirements of the tools which we will use for the downstream analysis.
Add chromosome prefix to vcf
Firstly, our next tool has some assumptions about our input VCFs. The tool expects the chromosome numbers to start with a prefix chr. Our VCFs only use the chromosome numbers however, the VCFs just use the chromosome numbers. This is due to a difference in reference genome used when creating the VCFs. To change the prefix in the VCFs we will use regex again.
Hands-on: Add chr prefix using regex
- Column Regex Find And Replace Tool: toolshed.g2.bx.psu.edu/repos/galaxyp/regex_find_replace/regexColumn1/1.0.1 with the following parameters:
- param-file “Select cells from”:
VCFs(output of Convert compressed file to uncompressed. tool)- “using column”:
Column: 1- In “Check”:
- param-repeat “Insert Check”
- “Find Regex”:
^([0-9MYX])- “Replacement”:
chr\1- param-repeat “Insert Check”
- “Find Regex”:
^(##contig=<.*ID=)([0-9MYX].+)- “Replacement”:
\1chr\2Comment: Explaining the regex.The two regex patterns might look complicated but they are quite simple if you break them down in components.
- The first check
^([0-9MYX])>chr\1adds thechrprefix to all the non-header line. The check can be broken down into the following elements:
^means that the pattern has to start at the beginning of the line not somewhere randomly in the line.[0-9MYX]means that at this position there should be a character from the list[], namely either a number from0-9or the characterM,Y, orX.- The replacement pattern
chr\1means that the prefixchrhas to be inserted before the first match\1. Here the first match refers to the pattern in the first brackets()around the list[0-9MXY].- The second check
(##contig=<.*ID=)([0-9MYX].+)>\1chr\2adds thechrprefix to the contig ids in the header lines. The check can be broken down into the following elements:
- The first match, the pattern in the first brackets
##contig=<.*ID=, matches the contig header lines, which start with##contig=<. It is followed by a match anything.for zero-or-more times*until it findsID=.- The second match, the pattern in the second brackets
[0-9MYX].+, matches the chromosome numbers and characters[0-9MYX]followed by a matching anything.for one-or-more times+.- The replacement pattern
\1chr\2means that the prefixchrhas to be inserted between the first match\1or##contig=<.*ID=and the second match\2or[0-9MYX].+.
Normalizing VCF
After adding the prefixes to the VCFs we need to normalize the variants in the VCF to standardize how the variants are represented within the VCF. This is a very important step, since the variants in the mother and daughter might be represented differently, which would mean that the causative variant might be overlooked!
One of the normalization steps is splitting multiallelic variants, 2 variants detected on the same position but on a different allele. Splitting these records will put the 2 variants on a separate line, that way the impact of the individual mutations can be evaluated. In addition, indels need to be left-aligned and normalized because that’s how they are stored in the annotation databases. An indel is left-aligned and normalized, according to Tan et al. 2015, “if and only if it is no longer possible to shift its position to the left while keeping the length of all its alleles constant” and “if it is represented in as few nucleotides as possible”.
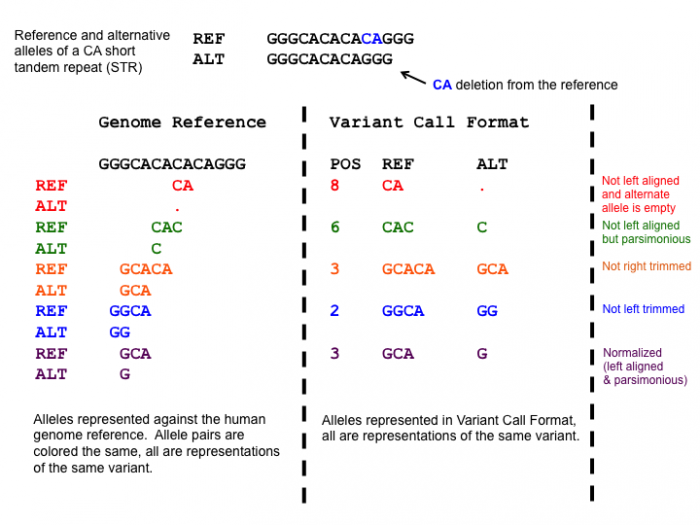
Hands-on: Normalize VCF
- bcftools norm Tool: toolshed.g2.bx.psu.edu/repos/iuc/bcftools_norm/bcftools_norm/1.9+galaxy1 with the following parameters:
- param-file “VCF/BCF Data”:
VCFs with chr prefix(output of Text reformatting tool)- “Choose the source for the reference genome”:
Use a built-in genome
- “Reference genome”:
Human (Homo sapiens): hg19- “Left-align and normalize indels?”:
Yes- “~multiallelics”:
split multiallelic sites into biallelic records (-)- In “Restrict all operations to”:
- “Regions”:
Do not restrict to Regions- “Targets”:
Do not restrict to Targets- “output_type”:
uncompressed VCFYou can have a look at the summary to check what changes were made. First, expand the output of bcftools norm (by clicking on the box) and it should be listed in the box. If not you can find it by clicking on the icon view details details and look at the output of the ToolStandard Error.
Filter NON_REF sites
After normalizing the VCFs we will filter out the variants with a NON_REF tag in the ALT column, the column which represents the mutated nucleotide(s). According to the header, these sites correspond to: “any possible alternative allele at this location”. So these sites are a sort of placeholders for potential variants. However we are not interested in this kind of variants and they slow our analysis down quite a lot, so we will filter them out.
Hands-on: Filter out NON_REF sites
- Filter Tool: Filter1 with the following parameters:
- param-file “Filter”:
Normalized VCFs(output of bcftools norm tool)- “With following condition”:
c5!='<NON_REF>'- “Number of header lines to skip”:
142This has to be set manually since the tool skips lines starting with ‘#’ automatically.
Question
- Why didn’t we filter out the NON_REF site directly after filtering? Have a look at the VCFs before and after normalization.
- Could we have filtered out the NON_REF sites earlier with a different program?
- The
<NON_REF>sites were sometimes also represented as a multi allelic variant e.g.,chr17 302 . T TA,<NON_REF>which would not be filtered out with the Filter Tool: Filter1 tool.- Possibly, if the
<NON_REF>variants were filtered out and if the<NON_REF>tag was removed from multi-allelic variants. However, the last task (splitting multi-allelic sites) can already be handled by bcftools norm Tool: toolshed.g2.bx.psu.edu/repos/iuc/bcftools_norm/bcftools_norm/1.9+galaxy1 and it might involve more sophisticated steps to properly split these variants.
Merge VCF collection into one dataset
Finally, we can merge the 3 separate files of the parents and patient into a single VCF. This will put overlapping variants on the same line by aligning the samples format column. If a sample misses a certain variant then on the line of that variant the sample’s format information will look like this: ./.:.:.:.:.:.. This makes it easier to find shared and missing variants between the parents and ofspring. A tool which can do this is the bcftools merge Tool: toolshed.g2.bx.psu.edu/repos/iuc/bcftools_merge/bcftools_merge/1.10 tool.
Hands-on: Merge VCFs
- bcftools merge Tool: toolshed.g2.bx.psu.edu/repos/iuc/bcftools_merge/bcftools_merge/1.10 with the following parameters:
- param-file “Other VCF/BCF Datasets”:
<NON_REF> filtered VCFs(output of Text reformatting tool)- In “Restrict to”:
- “Regions”:
Do not restrict to Regions- In “Merge Options”:
- “Merge”:
none - no new multiallelics, output multiple records instead- “output_type”:
uncompressed VCFComment: Checking the merged VCF.Check the merged VCF, now each line should contain 3 sample columns, namely
Case6F,Case6M, andCase6C. These columns represent the presence of the variant for the mother, father, and offspring.
Annotation
To understand what the effect of our variants are, we need to annotate our variants. We will use the tool SnpEff eff Tool: toolshed.g2.bx.psu.edu/repos/iuc/snpeff/snpEff/4.3+T.galaxy1 , which will compare our variants to a database of variants with known effects.
Annotate with SNPeff
Running SnpEff will produce the annotated VCF and an HTML summary file. The annotations are added to the INFO column in the VCF and the added INFO IDs (ANN, LOF, and NMD) are explained in the header. The summary files include the HTML stats file which contains general metrics, such as the number of annotated variants, the impact of all the variants, and much more.
Hands-on: Annotation with SnpEff
- SnpEff eff: Tool: toolshed.g2.bx.psu.edu/repos/iuc/snpeff/snpEff/4.3+T.galaxy1 with the following parameters:
- param-file “Sequence changes (SNPs, MNPs, InDels)”:
Merged VCF(output of bcftools merge tool)- “Output format”:
VCF (only if input is VCF)- “Genome source”:
Locally installed snpEff database
- “Genome”:
Homo sapiens : hg19- “spliceRegion Settings”:
Use Defaults- “Filter out specific Effects”:
No
Question
- How many variants got annotated?
- Is there something notable you can see from the HTML file?
- The number of variants processed is 209,143.
- Most variants are found in the intronic regions. However, this is to be expected since the mutations in intonic regions generally do not affect the gene.
GEMINI analyses
Next, we will transform our VCF into a GEMINI database which makes it easier to query the VCFs and to determine different inheritence patterns between the mother, father, and offspring. In addition, GEMINI will add even more annotations to the variants. This allows us to filter the variants even more which gets us to closer to the real causative variant. All these steps are performed by the GEMINI load Tool: toolshed.g2.bx.psu.edu/repos/iuc/gemini_load/gemini_load/0.20.1+galaxy2 tool. However, before we can load the VCF we also need to define a pedigree file.
Create a pedigree file describing the family trio
A pedigree file is a file that informs GEMINI which family members are affected by the disease and which sample name corresponds to what individual. This information is saved as a table containing information about the phenotype of the family.
- #family_id: Which family a row belongs to.
- name: The name of the sample, note this sample name has to overlap with the sample name in the VCF, see the last 3 columns of the VCF. However, for some reason the VCF contains the sample name from case 6 and not case 5. This was probably just a typo in the VCF, however here we just copy the sample name to our pedigree file.
- paternal_id: The sample name of the father or 0 for missing.
- maternal_id: The sample name of the mother or 0 for missing.
- sex: The sex of the person.
- phenotype: Wether or not the person is affected by the disease.
Hands-on: Creating the PED file
- Upload the pedigree file from below.
#family_id name paternal_id maternal_id sex phenotype FAM0001822 Case6M 0 0 2 2 FAM0001822 Case6F 0 0 1 1 FAM0001822 Case6C Case6F Case6M 2 2
- Open the Galaxy Upload Manager
- Select Paste/Fetch Data
Paste the file contents into the text field
- Press Start and Close the window
For more information on the PED file you can read the help section of the GEMINI load Tool: toolshed.g2.bx.psu.edu/repos/iuc/gemini_load/gemini_load/0.20.1+galaxy2 tool in the description, which can be found at the bottom of the page when clicking on the tool.
Load GEMINI database
Now we can transform the subsampled VCF and PED file into a GEMINI database. Note that this can take a very long time depending on the size of the VCF. In our case it should take around 30-40 minutes.
Hands-on: Transform VCF and PED files into a GEMINI database
- GEMINI load Tool: toolshed.g2.bx.psu.edu/repos/iuc/gemini_load/gemini_load/0.20.1+galaxy2 with the following parameters:
- param-file “VCF dataset to be loaded in the GEMINI database”:
SNPeff annotated VCF(output of SnpEff eff tool)- param-file “Sample and family information in PED format”: the pedigree file prepared above
Find inheritance pattern
With the GEMINI database it is now possible to identify the causative variant that could explain the breast cancer in the mother and daughter. The inheritance information makes it a bit easier to determine which tool to run to find the causative variant, instead of finding it by trying all the different inheritance patterns.
QuestionWhich inheritance pattern could have occurred in this family trio?
The available inheritance patterns can be found in the GEMINI inheritance pattern Tool: toolshed.g2.bx.psu.edu/repos/iuc/gemini_inheritance/gemini_inheritance/0.20.1 tool.
- Since both the daughter and mother are affected, and the father likely unaffected1, the mutation is most probably dominant. The disease could still be recessive if the father has one copy of the faulty gene, however this is less likely.
- The mutation is most likely not de-novo, since both the daughter and mother are affected.
- The mutation could be X-linked, however since the VCF only contain mutations on chromosome 17 it would practically be impossible.
- The disease could be compound heterozygous, however in that case the disease should be recessive which is less likely.
- A loss of heterozygosity (LOH) is also possible, since it is a common occurrence in cancer so this could be a viable inheritance pattern.
Based on these findings it would make sense to start looking for inherited autosomal dominant variants as a first step. If there are no convincing candidate mutations it would always be possible to look at the other less likely inheritance patterns, namely de-novo, compound heterozygous, and LOH events.
To find the most plausible causative variant we will use the GEMINI inheritance pattern Tool: toolshed.g2.bx.psu.edu/repos/iuc/gemini_inheritance/gemini_inheritance/0.20.1 tool. This tool allows us to select the most likely inheritance pattern (autosomal dominant). Below it is explained how to run the tool for this specific pattern, but you can always try other inheritence patterns if you are curious.
Hands-on: Run GEMINI autosomal dominant inhertiance pattern
- GEMINI inheritance pattern Tool: toolshed.g2.bx.psu.edu/repos/iuc/gemini_inheritance/gemini_inheritance/0.20.1 with the following parameters:
- param-file “GEMINI database”:
GEMINI database(output of GEMINI load tool)- “Your assumption about the inheritance pattern of the phenotype of interest”:
Autosomal dominant
- In “Additional constraints on variants”:
- param-repeat “Insert Additional constraints on variants”
- “Additional constraints expressed in SQL syntax”:
impact_severity != 'LOW'To filter variants on their functional genomic impact we will use the impact_severity feature. Here a low severity means a variant with no impact on protein function, such as silent mutations.- In “Family-wise criteria for variant selection”:
- “Specify additional criteria to exclude families on a per-variant basis”:
No, analyze all variants from all included families- In “Output - included information”:
- “Set of columns to include in the variant report table”:
Custom (report user-specified columns)
- “Additional columns (comma-separated)”:
chrom, start, ref, alt, impact, gene, clinvar_sig, clinvar_disease_name, clinvar_gene_phenotype, rs_ids
QuestionDid you find the causative variant in the output of the GEMINI inheritance pattern tool?
The only pathogenic variant related to breast cancer in the output, according to clinvar, is a SNP at chr17 at position 41215919 on the BRCA1 gene which transforms a G into a T, which is shown below.
chr17 41215919 G T missense_variant BRCA1 pathogenic,otherThis missense mutation transforms an alanine amino acid into a glutamine amino acid. Even though this variant has an unknown clinical significance in BRCA1 it was found to be among the top 10 SNPs which likely leads to breast cancer, according to Easton et al. 2007. You can find more info on this mutation by googling it’s rs_ID rs28897696.
Conclusion
In this tutorial we have illustrated how to easily download a dataset of interest savely and securely from the EGA using the HTSGET protocol. In addition, we performed a trio analysis to find the causative variant in an autosomal dominant inherited disease. We were able to find the causative variant by pre-processing and annotating our VCFs using the SnpEff and GEMINI annotations. With this workflow you can now easily analyse and find the causative variant(s) in many different family trios from any database which HTSGET can connect to.
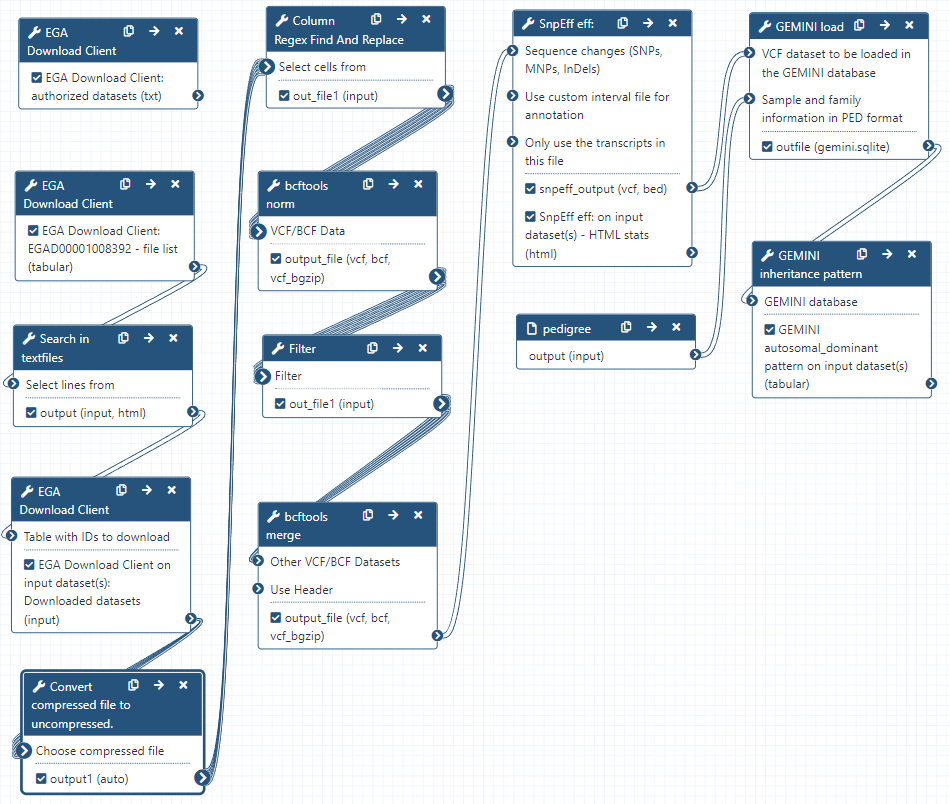
Workflow
Here is the final layout of the workflow. For more details you can download the workflow from the overview at the top of the page.
-
It is unlikely that the father has breast cancer, “For men, the lifetime risk of getting breast cancer is about 1 in 833” via cancer.org ↩
Key points
Downloading whole datasets with HTSGET is safe and easy with Galaxy.
Regex is a usefull tool for pre-processing VCF files.
Variant annotations allows us to strictly filter VCFs to find the causative variant.
Frequently Asked Questions
Have questions about this tutorial? Check out the FAQ page for the Variant Analysis topic to see if your question is listed there. If not, please ask your question on the GTN Gitter Channel or the Galaxy Help ForumUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
- Easton, D. F., A. M. Deffenbaugh, D. Pruss, C. Frye, R. J. Wenstrup et al., 2007 A Systematic Genetic Assessment of 1, 433 Sequence Variants of Unknown Clinical Significance in the BRCA1 and BRCA2 Breast Cancer–Predisposition Genes. The American Journal of Human Genetics 81: 873–883. 10.1086/521032
- Tan, A., G. R. Abecasis, and H. M. Kang, 2015 Unified representation of genetic variants. Bioinformatics 31: 2202–2204. 10.1093/bioinformatics/btv112
- Eberle, M. A., E. Fritzilas, P. Krusche, M. Källberg, B. L. Moore et al., 2017 A reference data set of 5.4 million phased human variants validated by genetic inheritance from sequencing a three-generation 17-member pedigree. Genome Res. 27: 157–164.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Jasper Ouwerkerk, Wolfgang Maier, Helena Rasche, Saskia Hiltemann, 2022 Trio Analysis using Synthetic Datasets from RD-Connect GPAP (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/variant-analysis/tutorials/trio-analysis/tutorial.html Online; accessed TODAY
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{variant-analysis-trio-analysis, author = "Jasper Ouwerkerk and Wolfgang Maier and Helena Rasche and Saskia Hiltemann", title = "Trio Analysis using Synthetic Datasets from RD-Connect GPAP (Galaxy Training Materials)", year = "2022", month = "10", day = "18" url = "\url{https://training.galaxyproject.org/training-material/topics/variant-analysis/tutorials/trio-analysis/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Batut_2018, doi = {10.1016/j.cels.2018.05.012}, url = {https://doi.org/10.1016%2Fj.cels.2018.05.012}, year = 2018, month = {jun}, publisher = {Elsevier {BV}}, volume = {6}, number = {6}, pages = {752--758.e1}, author = {B{\'{e}}r{\'{e}}nice Batut and Saskia Hiltemann and Andrea Bagnacani and Dannon Baker and Vivek Bhardwaj and Clemens Blank and Anthony Bretaudeau and Loraine Brillet-Gu{\'{e}}guen and Martin {\v{C}}ech and John Chilton and Dave Clements and Olivia Doppelt-Azeroual and Anika Erxleben and Mallory Ann Freeberg and Simon Gladman and Youri Hoogstrate and Hans-Rudolf Hotz and Torsten Houwaart and Pratik Jagtap and Delphine Larivi{\`{e}}re and Gildas Le Corguill{\'{e}} and Thomas Manke and Fabien Mareuil and Fidel Ram{\'{\i}}rez and Devon Ryan and Florian Christoph Sigloch and Nicola Soranzo and Joachim Wolff and Pavankumar Videm and Markus Wolfien and Aisanjiang Wubuli and Dilmurat Yusuf and James Taylor and Rolf Backofen and Anton Nekrutenko and Björn Grüning}, title = {Community-Driven Data Analysis Training for Biology}, journal = {Cell Systems} }