Generación de una matriz de datos de secuenciación de ARN de células únicas utilizando Alevin
 Wendi Bacon
Wendi Bacon Jonathan Manning
Jonathan Manning Patricia Carvajal López
Patricia Carvajal López Alejandra Escobar-Zepeda
Alejandra Escobar-ZepedaDescripción GeneralPreguntas:Objetivos:
Tengo algunos archivos FASTQ de secuenciación de ARN de células únicas los cuales quiero analizar. ¿Por dónde empiezo?
Requisitos:
Repetir la generación de una matriz para datos de secuenciación de ARN de células únicas obtenidos a partir de técnicas de goteo
Aplicar combinación de datos y edición de metadatos en diseños experimentales específicos
Interpretar gráficos de control de calidad (QC) para poder tomar decisiones fundamentadas en umbrales de célula
Encontrar información relevante en archivos GTF que esté asociada a las particularidades del estudio e incluirla en los metadatos de la matriz de datos
- Introduction to Galaxy Analyses
- Sequence analysis
- Quality Control: slides slides - tutorial hands-on
- Mapping: slides slides - tutorial hands-on
- Transcriptomics
- An introduction to scRNA-seq data analysis: slides slides
- Understanding Barcodes: tutorial hands-on
Duración estimada: 3 horasNivel: Avanzado AdvancedMateriales de apoyo:
- Topic Overview slides
- Conjuntos de datos
- Flujos de trabajos
- FAQs
- instances Disponible en estas instancias de Galaxy
Última modificación: Sep 28, 2022
 Preguntas:
Preguntas:
Introduction
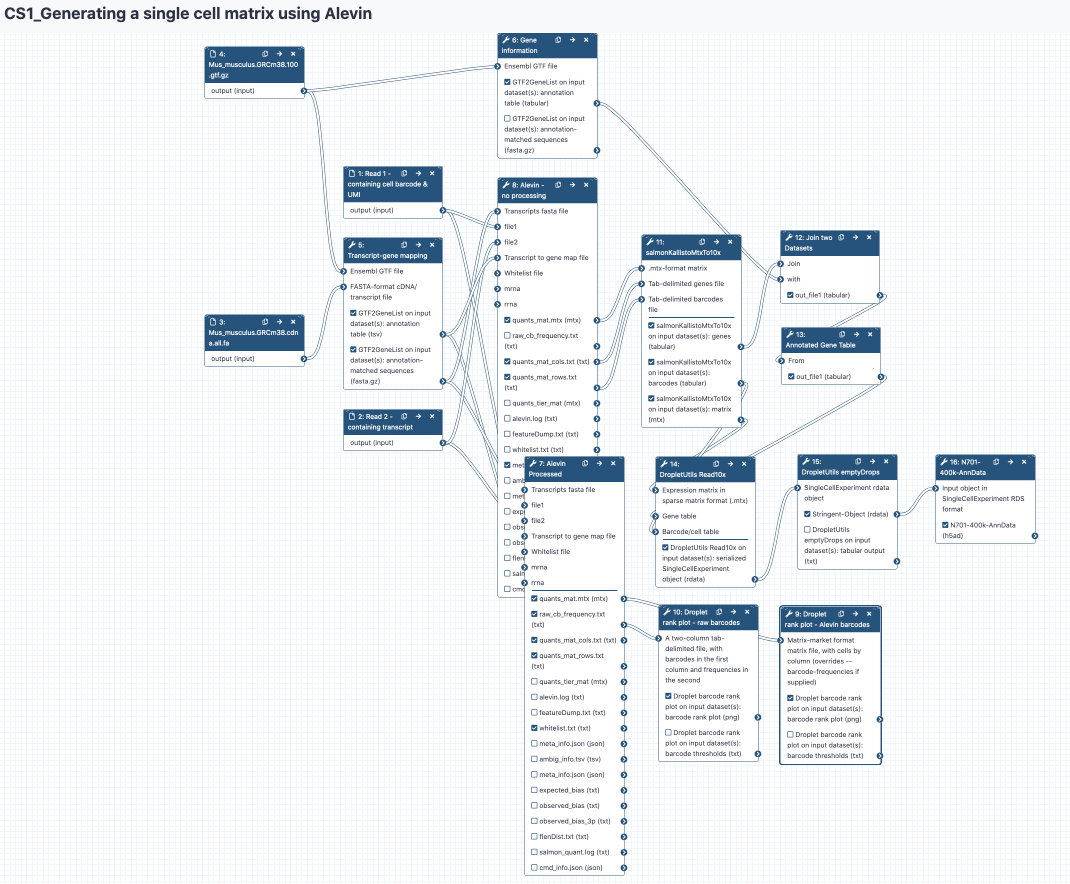
Este tutorial te ayudará a pasar de datos crudos de secuenciación en archivos FASTQ a una matriz de datos en formato AnnData donde cada célula es una fila y cada gen es una columna. Pero, ¿Qué es una matriz de datos y cuál es el formato AnnData? Lo averiguaremos a su debido tiempo. Enfatizamos que este es el primer paso para procesar datos de secuenciación de células únicas para poder realizar su análisis.
De momento, en tus archivos de secuenciación tienes un montón de cadenas del tipo ATGGGCTT, etc. y lo que necesitas saber es cuántas células tienes y qué genes aparecen en ellas. En la segunda parte de este tutorial abordaremos la combinación de archivos FASTQ y el cómo añadir metadatos (por ejemplo, SEXO o GENOTIPO) para análisis posteriores. Estos son los pasos que requieren más recursos computacionales en los análisis de células únicas, ya que partimos de cientos de millones de lecturas, cada una de ellas con cuatro líneas de texto. Posteriormente, en el análisis, estos datos se convertirán en simples conteos de genes, por ejemplo ‘La célula A tiene 4 GAPDHs’ (‘Cell A has 4 GAPDHs’), que es mucho más sencillo de almacenar.
Debido a la enorme cantidad de datos, hemos reducido la resolución de los archivos FASTQ para poder acelerar el análisis. Una vez que hemos aclarado este punto, todavía tienes que mapear enormes cantidades de lecturas al inmenso genoma murino, así que ¡ve por una taza de café y prepárate para iniciar el análisis!
AgendaEn este tutorial abordaremos:
Generar una matriz
En esta sección te mostraremos los principios de la fase inicial del análisis de Secuenciación de ARN de células únicas, que se basa en generar mediciones de expresión en una matriz. Por simplicidad, nos referiremos a este análisis por sus siglas en inglés scRNA-Seq (single-cell RNA-Seq). Nos concentramos en la metodología basada en goteo (en lugar de las metodologías basadas en placas), ya que es el proceso con más diferencias con respecto a los enfoques convencionales desarrollados para secuenciación de ARN general.
Los datos provenientes de metodologías de goteo están constituidos por tres componentes: códigos de barras, identificadores únicos moleculares (Unique molecular Identifier, o UMIs por sus siglas en inglés) y lecturas de ADN codificante (proveniente de ADN complementario o cDNA). Para poder generar cuantificaciones a nivel celula necesitaremos:
- Procesar los códigos de barras, identificar cuáles corresponden a células ‘reales’, cuáles son meros artefactos, y posiblemente corregir códigos de barras que pudiesen ser producto de errores de secuenciación por medio de comparaciones con secuencias de mayor frecuencia.
- Mapear secuencias biológicas a su genoma o transcriptoma de referencia.
- Eliminar duplicados usando UMIs.
Este solía ser un proceso complejo que involucraba múltiples algoritmos, o que se realizaba con métodos dedicados a tecnologías específicas (como la herramienta ‘Cellranger’ para 10X); pero ahora el proceso es más simple gracias al surgimiento de otros métodos. En el momento de seleccionar una metodología para tu proyecto podrías considerar las siguientes herramientas:
- STARsolo - una variante del popular método de alineamiento de genoma ‘STAR’ que es específica para el análisis de datos de secuenciación de ARN de células únicas basados en técnicas de goteos (dscRNA-Seq). Produce resultados muy cercanos a los de Cellranger (que a su vez utiliza STAR en parte de sus procesos).
- Kallisto/ bustools - desarrollado por los creadores del método de cuantificación de transcriptoma, Kallisto.
- Alevin - otro método de análisis de transcriptoma desarrollado por los autores de la herramienta ‘Salmon’.
Utilizaremos Alevin Srivastava et al. 2019 con propósitos demostrativos, sin embargo no avalamos ningún método en particular.
Comentario: Comentario
- Notas sobre la traducción y uso de términos técnicos En este tutorial manejaremos algunos términos en el idioma original ya que simplificará la búsqueda posterior de información sobre el tema. Estas notas aparecerán en este tipo de recuadros y los términos estarán listados con la viñeta “•”.
- scRNA-Seq, secuenciación de ARN de células únicas
- dscRNA-Sea, secuenciación de ARN de células únicas
- basados en técnicas de goteos
- RNA-Seq, Secuenciación de ARN
- UMIs, Identificadores únicos moleculares
Obtener datos
Hemos puesto a tu disposición un conjunto de datos de muestra para que practiques con ellos. Estos datos son un subconjunto de lecturas de datos provenientes de ratones con restricción de crecimiento fetal Bacon et al. 2018 (ver aquí el estudio de células únicas disponible en la base de datos ‘Expression Atlas’ y aquí la remisión del proyecto a la plataforma ArrayExpress).
Utilizamos la tecnología Drop-seq para este estudio. Sin embargo, el análisis que abordaremos en este tutorial es casi idéntico al que se realiza al utilizar la tecnología 10x. Estos datos no han sido curados meticulosamente, los datos del tutorial son algo caóticos ya que provienen de un experimento real. Necesitan filtrado urgentemente ya que contienen ARNs que le agregan ruido de fondo, sin embargo, te darán la oportunidad de practicar un análisis como si fuera el tuyo propio.
Puedes descargar las lecturas de muestra y su anotación asociada desde el repositorio Zenodo. También puedes importar este historial de ejemplo. ¿Cómo bajamos la resolución de estos archivos FASTQ? ¡Descubre aquí la historia de cómo se llevó esto a cabo! Adicionalmente, necesitarás un transcriptoma (en formato FASTA) contra el cual podrás mapear tus lecturas, así como la información génica de cada transcrito (en un archivo tipo GTF). Adicionalmente, estos archivos están disponibles en el historial anteriormente mencionado, al igual que en los enlaces de Zenodo mostrados en la parte inferior de este párrafo, así que puede que tarden un buen rato en importarse. Puedes acceder a Ensembl si deseas bajar datos para tu especie de interés.
Práctica: Práctica: Cargar datos - Parte 1
- Crear un historial nuevo para este tutorial
Importar la tabla de diseño experimental, las lecturas de secuenciación 1 y 2, y los archivos GTF y fasta desde Zenodo
https://zenodo.org/record/4574153/files/Experimental_Design.tabular https://zenodo.org/record/4574153/files/Mus_musculus.GRCm38.100.gtf.gff https://zenodo.org/record/4574153/files/Mus_musculus.GRCm38.cdna.all.fa.fasta https://zenodo.org/record/4574153/files/SLX-7632.TAAGGCGA.N701.s_1.r_1.fq-400k.fastq https://zenodo.org/record/4574153/files/SLX-7632.TAAGGCGA.N701.s_1.r_2.fq-400k.fastq
- Copia los enlaces
Abre el manejador de carga de datos de Galaxy (galaxy-upload en la parte superior derecha del panel de herramientas)
- Selecciona ‘Pegar/Traer datos’ Paste/Fetch Data
Copia los enlaces en el campo de textos
Presiona ‘Iniciar’ Start
Close Cierra la ventana.
- Galaxy utiliza los URLs como nombres de forma predeterminada , así que los tendrás que cambiar a algunos que sean más útiles o informativos.the window
- Cambiar el nombre galaxy-pencil de los conjuntos de datos
Preguntas: PreguntasDale un vistazo a los archivos que ahora están en tu historial.
- ¿Cuál de los archivos FASTQ crees que contiene las secuencias de los códigos de barras?
- Dada la metodología química que implica este estudio, ¿tienen las lecturas de códigos de barras/UMIs la longitud correcta?
- ¿A que se refiere el término ‘N701’?
- La lectura 1 (SLX-7632.TAAGGCGA.N701.s_1.r_1.fq-400k) contiene el código de barras de la célula y el UMI ya que es significativamente más corta (¡solo 20pb!), en comparación con r_2 que es la lectura más larga de transcrito. Cambiaremos de nombre a estos archivos y los llamaremos N701-Read1 y N701-Read2 para hacer más claro el análisis.
- Puedes ver que la lectura 1 solo tiene 20pb de longitud, ya que el código de barras de Drop-Seq es de 12pb de longitud y el UMI de 8pb. ¡Esto es correcto! Pero ten precaución, la tecnología 10x Chromiun (y muchas otras) cambian sus reactivos (y longitudes de cebadores y adaptadores) con el paso del tiempo. En particular, ten esto en cuenta cuando accedas a datos públicos, verifica y asegurate de que estés utilizando los números correctos.
- El término ‘N701’ se refiere al índice de la lectura. Esta muestra se tomó junto con otras seis, cada una de ellas se denotó con un índice Nextera (N70X). Posteriormente, esto te proporcionará información del lote del que provienen. Observa el archivo ‘Diseno experimental’ (‘Experimental design’), notarás que la muestra N701 proviene del timo de neonato macho tipo normal (‘wild-type’).
Generar un mapa de correspondencia de transcritos a genes
En el análisis de Secuenciación de ARN de células únicas tomamos por defecto la cuantificación a nivel génico, en lugar de a nivel transcrito. Esto significa que los niveles de expresión de una molécula de ARN con splicing alternativo son combinados con el propósito de generar valores a nivel génico. Las técnicas de scRNA-Seq basadas en goteo solo muestrean un extremo de cada transcrito, por tanto carecen de cobertura completa de moléculas, la cual es requerida para poder cuantificar con exactitud las diversas isoformas de los transcritos.
Para poder generar las cuantificaciones a nivel génico con base en la cuantificación de transcriptoma, la herramienta Alevin y otras similares requieren de la conversión entre identificadores de transcritos e identificadores de genes. Podemos derivar una conversión transcritos-genes a partir de anotaciones génicas disponibles en plataformas de recursos genómicos como Ensembl. Los transcritos en este tipo de listas necesitan coincidir con los que usaremos posteriormente para construir un índice binario de transcriptoma. Si estás utilizando controles tipo ‘spike-in’ necesitarás añadirlos al transcriptoma y al mapeo de transcritos a genes.
Notarás en tus datos de ejemplo que la anotación de referencia murina se obtuvo en formato GTF desde Ensembl. Esta anotación contiene genes, exones, transcritos y todo tipo de información adicional de las secuencias. Utilizaremos esta información para generar el mapeo de correspondencia transcrito/genes. Esto lo haremos por medio del traspaso de información a una herramienta que extrae exclusivamente los identificadores de transcrito que necesitamos.
Comentario: ComentarioNota sobre la traducción y uso de términos técnicos
- Spike-in, transcrito de ARN de cantidad y secuencia conocida utilizado para calibrar mediciones en ensayos de hibridación de ARN. Nos referiremos a este control con su nombre en el idioma inglés ya que su traducción no es utilizada comúnmente.
Preguntas: Preguntas¿Cuál de los ‘atributos’ en la última columna de los archivos GTF contiene los identificadores de transcrito y de gen?
El archivo está organizado de tal modo que la última columna (con el nombre ‘Group’ en el encabezado) contiene una gran cantidad de información: attribute1 “información asociada con el atributo1”;attribute2 “información asociada con el atributo 2” etc.
A gene_id y transcript_id les sigue “ensembl gene_id” y “ensembl transcript_id”
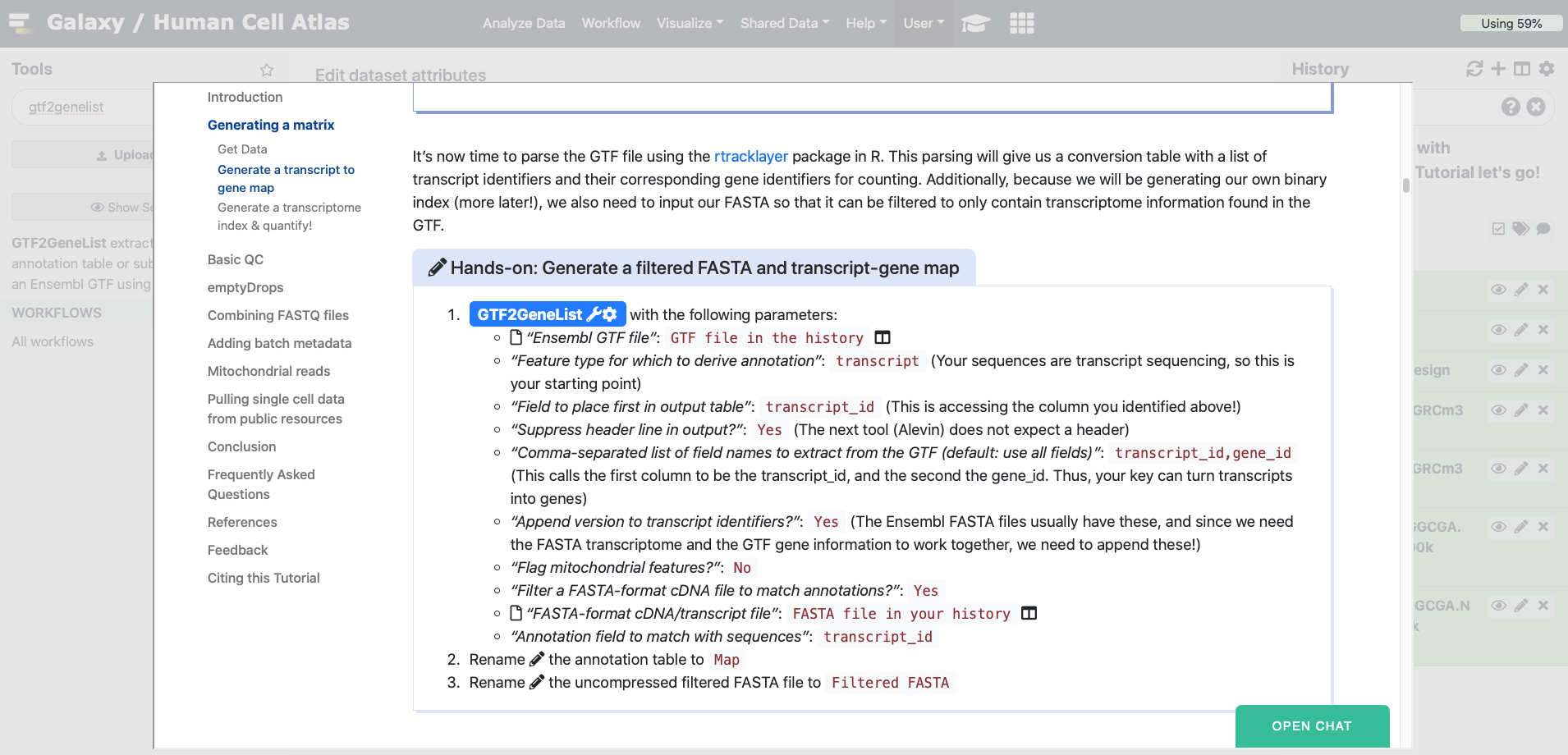
Ahora es el momento de analizar el archivo GTF utilizando el paquete de R rtracklayer. Este análisis proporcionará una tabla de conversión con un listado de identificadores de transcritos y sus genes correspondientes para hacer conteos. Adicionalmente, ya que generaremos nuestro propio índice binario (más sobre esto en secciones posteriores), también necesitaremos proporcionar nuestro archivo FASTA para que pueda ser filtrado y que al final solo contenga la información del transcriptoma que está contenida en el archivo GTF.
Práctica: Práctica: Generar un archivo FASTA filtrado y un mapa de correspondencia de transcritos a genes
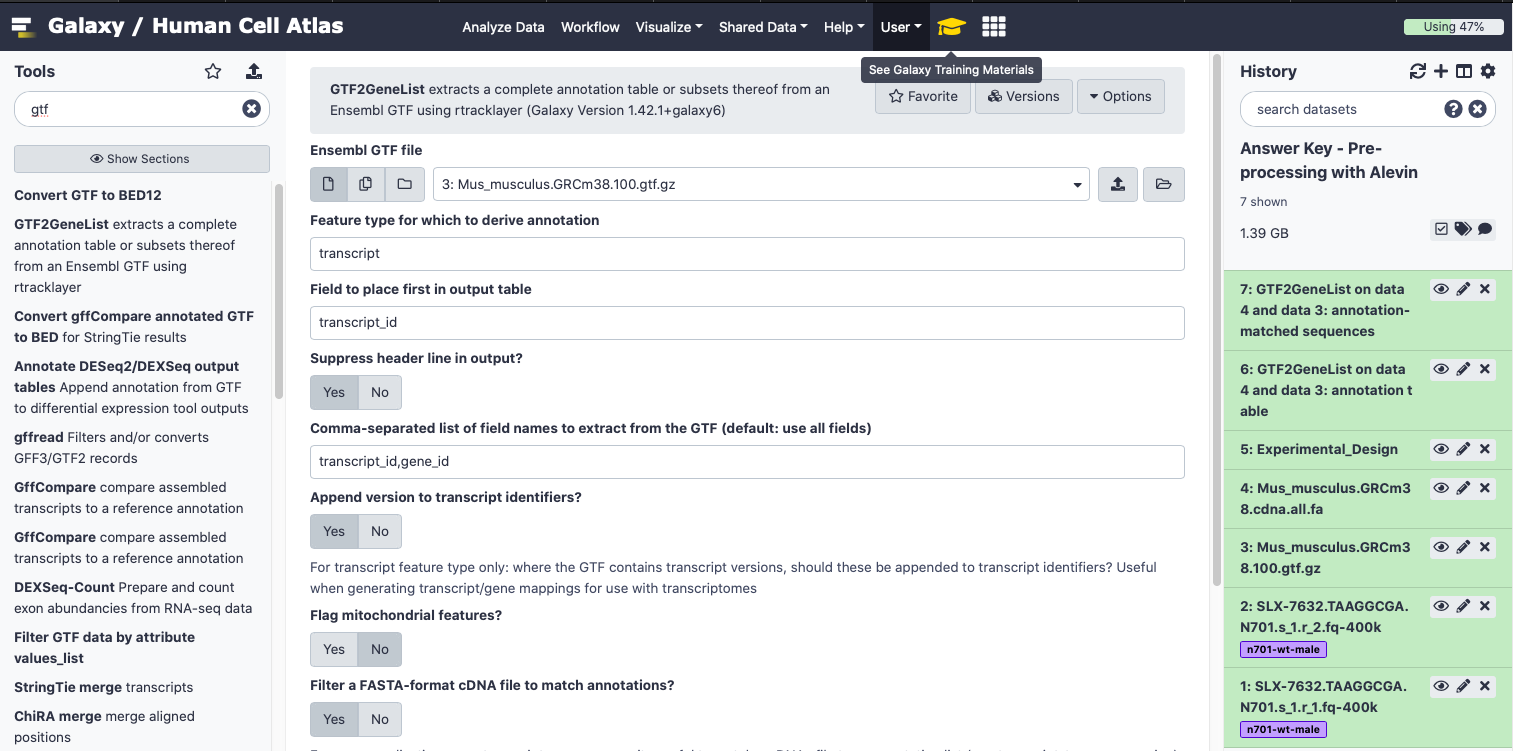
- Ejecutar la herramienta GTF2GeneList GTF2GeneList Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/gtf2gene_list/_ensembl_gtf2gene_list/1.42.1+galaxy6 utilizando los siguiente parámetros:
- param-file “Ensembl GTF file”:
GTF file in the historygalaxy-history- “Feature type for which to derive annotation”:
transcript(Tus secuencias provienen de secuenciación de transcriptoma, por tanto este es tu punto inicial)- “Field to place first in output table”:
transcript_id(Esto da acceso a la columna que identificaste en la parte anterior)- “Suppress header line in output?”:
Yes(La siguiente herramienta (Alevin) no toma encabezados)- “Comma-separated list of field names to extract from the GTF (default: use all fields)”:
transcript_id,gene_id(Esto hace que la primera columna sea transpript_id, y la segunda sea gene_id. Por tanto, tu clave puede convertir transcritos a genes)- “Append version to transcript identifiers?”:
Yes(Por lo general el archivo FASTA de Ensembl contiene esta información, y ya que necesitaremos que el transcriptoma en formato FASTA y la información de genes del archivo GTF trabajen en conjunto, necesitaremos añadir la información de uno al final del otro)- “Flag mitochondrial features?”:
No- “Filter a FASTA-format cDNA file to match annotations?”:
Yes- param-file “FASTA-format cDNA/transcript file”:
FASTA file in your historygalaxy-history- “Annotation field to match with sequences”:
transcript_idCambiar el nombre galaxy-pencil de la tabla de anotación a
Map- Cambiar el nombre galaxy-pencil del archivo FASTA filtrado - no comprimido a
Filtered FASTA
Generar el índice de un transcriptoma y cuantificar
Alevin reduce a un solo proceso los pasos requeridos para realizar dscRNA-Seq. Dichas herramientas requieren comparar las secuencias de tu muestra a una referencia que contenga todas las secuencias probables de transcritos (un ‘transcriptoma). Esto contendrá las secuencias biológicas de los transcritos conocidos en una especie determinada, y quizás también contendrá secuencias técnicas como ‘spike ins’.
Alevin necesita convertir las secuencias de texto contenidas dentro del formato FASTA a algo con lo que pueda realizar búsquedas rápidamente dentro del transcriptoma, ese ‘algo’ es un archivo llamado ‘índice’ (‘index’). El índice es un archivo binario (un tipo de archivos optimizados para el uso de ordenadores y que no es legible ‘por humanos’), pero permite que Alevin realice búsquedas rápidas. El índice puede variar entre experimentos debido al tipo de secuencias técnicas y biológicas que necesitamos incluir en él, y ya que frecuentemente queremos utilizar las referencias más actualizadas, ya sea que provengan de Ensembl o NCBI, a menudo pudiésemos terminar reconstruyendo los índices. El generar estos índices requiere mucho tiempo. Échale un vistazo al archivo FASTA no comprimido para que veas cómo es la estructura inicial.
Ahora tenemos:
- Lecturas de códigos de barras/UMIs
- Lecturas de cDNA
- Mapeo de correspondencias de transcritos a genes
- Archivo FASTA filtrado
Ahora podemos ejecutar Alevin. Esta herramienta no aparecerá en las búsquedas dentro de algunas de las instancias públicas. Si esto sucede, haz click sobre la pestaña Single Cell en la parte izquierda de la pantalla y desplázate hacia abajo hasta encontrar la herramienta Alevin. Consejo: Si haces click sobre las herramientas (tools) dentro de la opción ‘tutorial’ de Galaxy siempre tendrás la versión correcta de la herramienta. En este caso: Galaxy Version 1.3.0+galaxy2 - debe ser la versión por defecto; si no lo es, haz click sobre ‘Versiones’ (‘Versions’) y escoge dicha versión.
Práctica: Practica: Ejecutando Alevin
Alevin Tool: toolshed.g2.bx.psu.edu/repos/bgruening/alevin/alevin/1.3.0+galaxy2
Preguntas: PreguntasIntenta dar valores a los parámetros de Alevin utilizando lo que sabes por el momento.
La documentación sobre ‘Tipos de bibliotecas de fragmentos’ (‘Fragment Library Types‘) de de la herramienta salmón, el ejecutar el comando de Alevin (salmon.readthedocs.io/en/latest/library_type.html y salmon.readthedocs.io/en/latest/alevin.html) nos serán de ayuda en este caso; aunque ten en cuenta que la imagen ahí se dibuja con el ARN 5’ en la parte superior, mientras que en este protocolo de scRNA-Seq el segmento polyA es capturado por su extremo 3’, y, por lo tanto, efectivamente la hebra inferior o inversa.)
- “Select a reference transcriptome from your history or use a built-in index?”:
Use one from the history
- Vas a generar el índice binario utilizando tu archivo FASTA filtrado
- param-file “Transcripts FASTA file”:
Filtered FASTA- “Single or paired-end reads?”:
Paired-end- param-file “file1”:
N701-Read1- param-file “file2”:
N701-Read2- “Relative orientation of reads within a pair”:
Mates are oriented towards each other (IR)- “Specify the strandedness of the reads”:
read comes from the reverse strand (SR)- “Protocol”:
DropSeq Single Cell protocol- param-file “Transcript to gene map file”:
Map- “Retrieve all output files”:
Yes- In “Optional commands”:
- “dumpFeatures”:
Yes- “dumpMTX”:
Yes
Comentario: ComentarioNotas sobre la traducción de algunos de los valores de los parámetros: En este tutorial manejaremos algunos términos en el idioma original ya que simplificará la búsqueda posterior de información sobre el tema. Estas notas aparecerán en estos recuadros y los términos estarán listados con la viñeta “•”.
- “Select a reference transcriptome from your history or use a built-in index?”: Use one from the history
- “¿Seleccionar un transcriptoma de referencia desde tu historial o utilizar un índice pre-integrado?”:
Utilizar uno del historial- “Transcripts FASTA file”:
Filtered FASTA
- “Archivo FASTA de transcritos”:
FASTA filtrado- “Single or paired-end reads?”:
Paired-end
- “¿Lecturas single-end o paired-end?”:
Paired-end- “Relative orientation of reads within a pair”:
Mates are oriented towards each other (IR)`
- “Orientación relativa de las lecturas dentro de un par”:
Las lecturas pares están orientadas unas hacia las otras (IR)`- “Specify the strandedness of the reads”:
read comes from the reverse strand (SR)`
- “Especificar la direccionalidad de las lecturas”:
las lecturas provienen de las cadenas inversas (SR)`- “Retrieve all output files”:
Yes
- “Recobrar todos los archivos de salida”:
Sí`
Comentario: ¿Qué sucede si estoy procesando una muestra 10x??En Alevin, “Protocol” (Protocolo) es el parámetro principal que debe cambiarse para una muestra 10X Chromium. Simplemente selecciona los reactivos correspondientes a la química de 10x en lugar de Drop-seq.
Esta herramienta tomará algo de tiempo para ejecutarse. Alevin produce muchos archivos de salida, no utilizaremos todos estos archivos. Puedes consultar la documentación de Alevin si deseas saber más sobre estos archivos, sin embargo, los archivos que más nos interesan son:
- La matriz generada (quants_mat.mtx.gz - el conteo de genes y células)
- Los identificadores de fila
cell/ barcode(quants_mat_rows.txt), y - Las etiquetas en la columna
gene(quants_mat_cols.txt).
Este es el formato “matrix market” (MTX).
Preguntas: PreguntasEcha un vistazo a los diversos archivos generados después de ejecutar Alevin. ¿Puedes localizar las siguientes dos cosas?…
- ¿Cuál es la tasa de mapeo?
- ¿Cuántas células están presentes en la matriz de salida?
- Inspecciona galaxy-eye el archivo param-file meta_info.json. Puedes ver que la tasa de mapeo es un insignificante
24.75%. Esta tasa es terrible. ¿Por qué sucede esto? Recuerda que este archivo fue submuestreado, siendo específicos, solo tomamos las últimas 400,000 lecturas del archivo FASTQ. La tasa general de mapeo del archivo es de alrededor del 50%, que sigue siendo una tasa muy baja, pero en general se pueden esperar tasas de mapeos ligeramente menores para muestras que fueron procesadas durante los inicios de las técnicas Drop-Seq y la secuenciación de ARN de células únicas. Actualmente las muestras procesadas con la técnica 10x son mucho mejores. Después de todo, los datos que estamos utilizando son reales, no son datos de prueba.- Inspecciona galaxy-eye el archivo param-file ‘quants_mat_rows.txt’, y podrás ver que contiene
2163líneas. Las filas hacen referencia a las células en la matriz de correspondencia de células a genes. Según esta estimación (aproximada), tu muestra contiene 2163 células.
Aviso: ¡Precaucion!: De aquí en adelante selecciona la entrada apropiada.Asegurate de usar el archivo quants_mat.mtx.gz, NO EL ARCHIVO quants_tier.mtx.gz.
congratulations Felicidades - ¡has generado una matriz de expresión! Podríamos terminar en este punto, pero es necesario verificar la calidad de los datos, y una de las cosas que podemos hacer es visualizar un gráfico de rangos de los códigos de barras.
Control de calidad básico
La pregunta que buscamos contestar aquí es: “En su mayoría, ¿tenemos una sola célula por gota?”. Este es el principal objetivo, pero no es del todo sencillo obtener exactamente una sola célula por cada gota. En algunas ocasiones casi ninguna célula logra depositarse en las gotas, en otras ocasiones tenemos demasiadas células por gota. Cuando menos deberíamos poder distinguir fácilmente las gotas que contienen células de las que no las contienen.
Práctica: Práctica: Generar un gráfico inicial de control de calidad (QC)
- Droplet barcode rank plot Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/droplet_barcode_plot/_dropletBarcodePlot/1.6.1+galaxy2 Gráfico de rangos de códigos de barras obtenido por técnicas de goteo (Droplet barcode rank plot) con los siguientes parámetros:
- “Input MTX-format matrix?”:
No- param-file “A two-column tab-delimited file, with barcodes in the first column and frequencies in the second”:
raw_cb_frequencies.txt- “Label to place in plot title”:
Barcode rank plot (raw barcode frequencies)- Cambiar el nombre galaxy-pencil a la imagen de salida
Barcode Plot - raw barcode frequencies
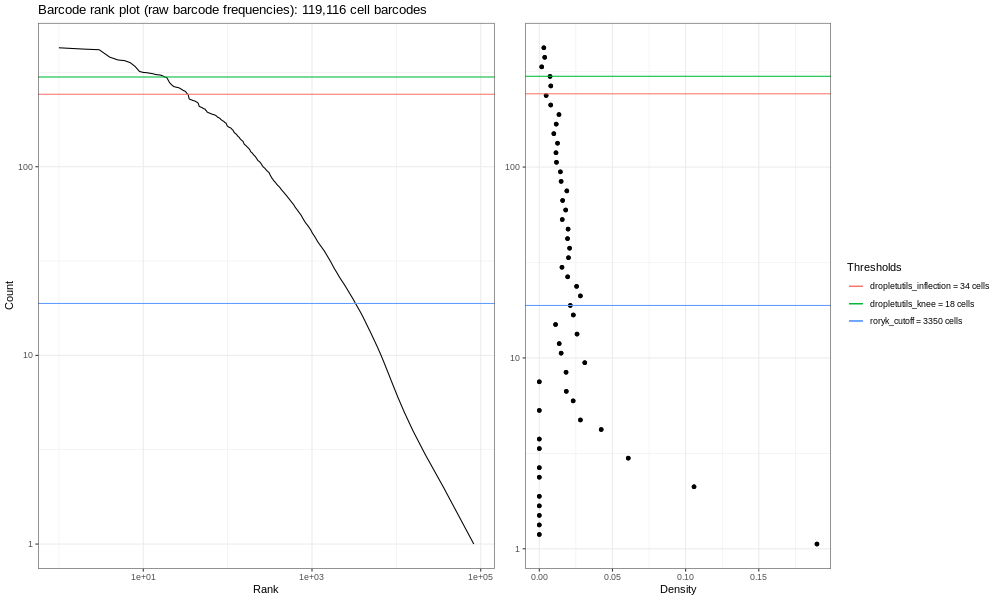
La imagen aquí generada (4000k) no es muy informativa - pero ten en cuenta que tan solo estás manejando una fracción de las lecturas. Si procesas la muestra completa (que involucra los mismos pasos mencionados en la parte superior, pero que tardaría mucho más tiempo) obtendrás la imagen siguiente.
Esta es la formulación del gráfico de código de barras que basamos en una discusión que entablamos con miembros de la comunidad científica. Los gráficos de líneas suaves de la izquierda son los principales; estos gráficos muestran, clasificados de los más bajos a los más altos, los conteos de UMIs para códigos de barras individuales. Esperamos una fuerte caída entre las gotas que contienen células y las gotas vacías o que solo contienen restos celulares. Este no es un conjunto de datos ideal, así que en perspectiva, en un mundo ideal un conjunto de datos muy limpio proveniente de procesados 10x, los datos se asemejarían un poco más a la siguiente imagen del atlas de pulmón (ver aquí el estudio del Atlas de Expresión de Células Únicas y la remisión del proyecto aquí).
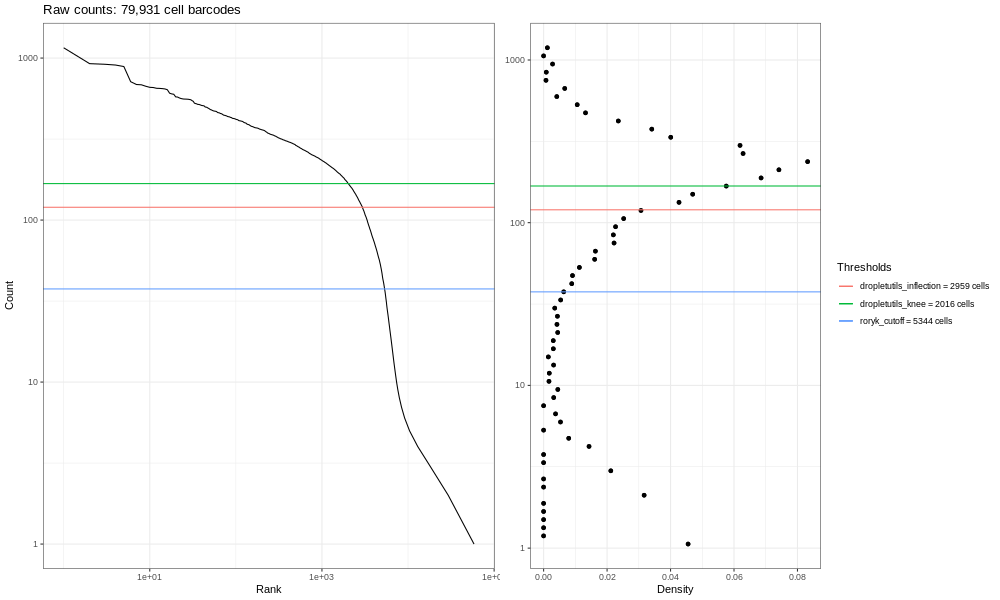
En este gráfico puedes ver más claramente una flexión tipo “rodilla”, mostrando el corte entre las gotas vacías y las gotas que contienen células.
A la derecha encontramos los gráficos de densidad de la primera, y los umbrales generados ya sea utilizando dropletUtils o por medio del método descrito en la discusión que se mencionó con anterioridad (en la parte superior). Podremos utilizar cualquiera de estos umbrales para seleccionar células, asumiendo que cualquier medición con conteos menores es una célula válida. Alevin hace algo similar por defecto, y podemos aprender algo de esto graficando únicamente los códigos de barras que retiene Alevin.
Práctica: Práctica: Obtener el gráfico de código de barras de Alevin
- Droplet barcode rank plot Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/droplet_barcode_plot/_dropletBarcodePlot/1.6.1+galaxy2 Genera el gráfico de código de barras basado en goteos utilizando los siguientes parámetros:
- “Input MTX-format matrix?”:
Yes- “Matrix-market format matrix file, with cells by column (overrides –barcode-frequencies if supplied)”:
quants_mat.mtx- “For use with –mtx-matrix: force interpretation of matrix to assume cells are by row, rather than by column (default)”:
Yes- “Label to place in plot title”:
Barcode rank plot (Alevin-processed)- “Number of bins used in barcode count frequency distribution”:
50- “Above-baseline multiplier to calculate roryk threshold”:
1.5- Cambiar el nombre galaxy-pencil de la imagen de salida
Barcode Plot - Alevin processed barcodes
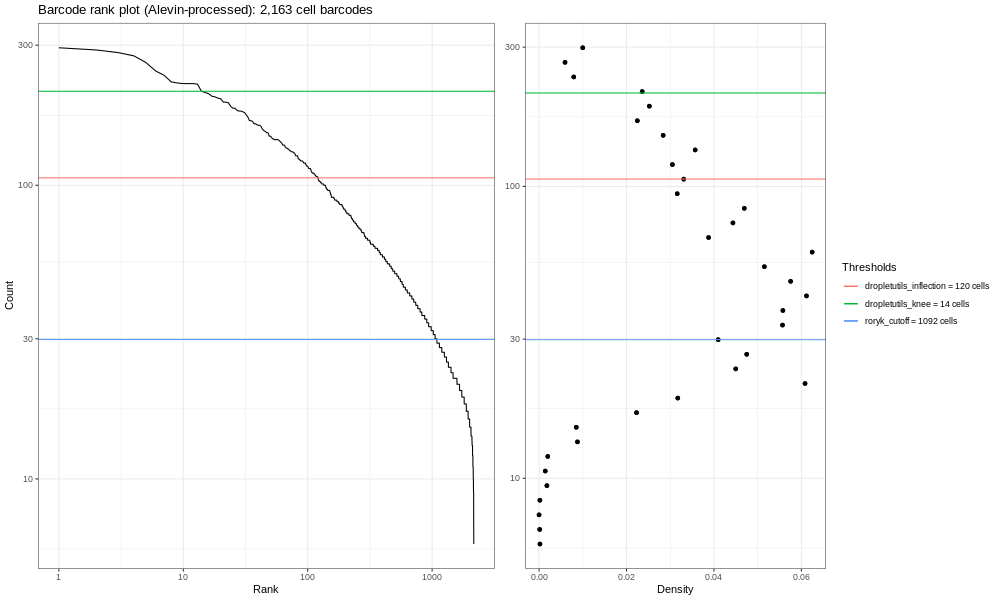
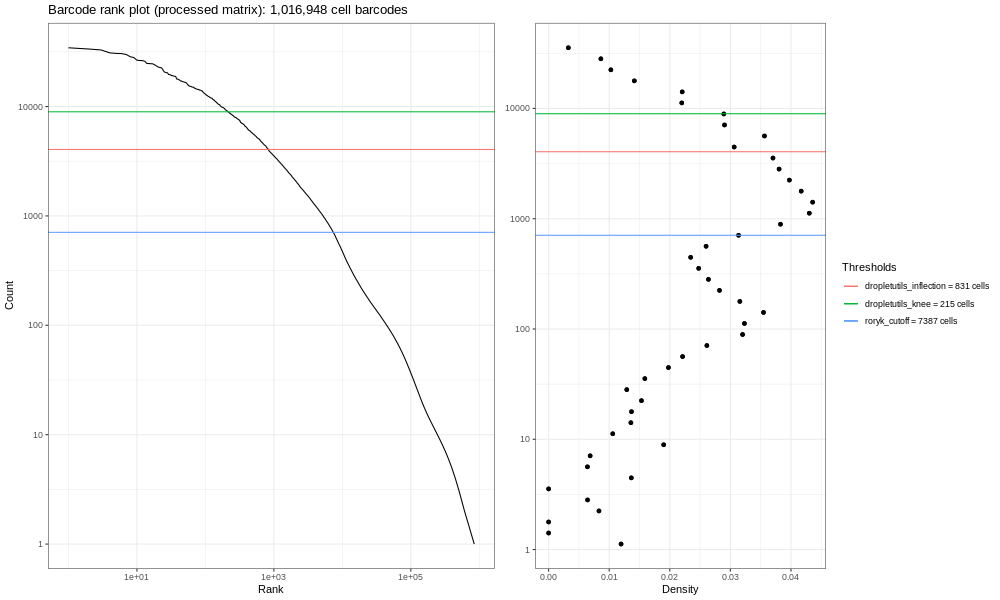
Y la muestra completa se ve como la siguiente figura:
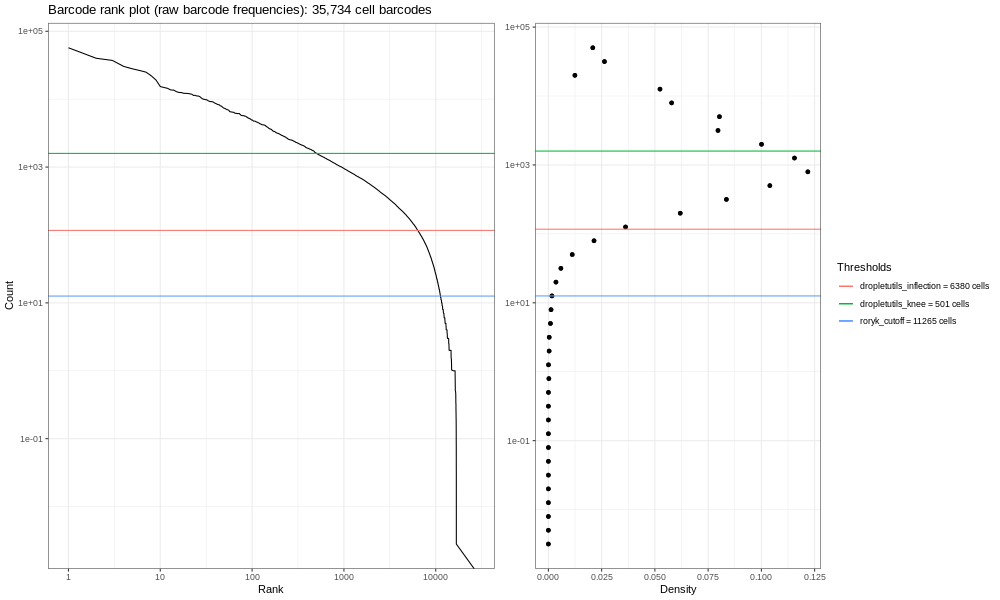
Y concluyendo, he aquí el gráfico del atlas de pulmón.
Debes ver una caída casi vertical de la curva, que es donde Alevin truncó la distribución (después de haber excluido muchos códigos de barra celulares que tuvieron <10 UMI, Alevin posteriormente selecciona un umbral basándose en la curva y elimina los códigos de barras con menos UMIs)
Este método de ‘detección intensa’ funciona relativamente bien en experimentos con características relativamente sencillas. Pero algunas poblaciones presentan dificultades (¡como en nuestra muestra!). Por ejemplo, si nos basamos únicamente en los conteos de códigos de barras, puede ocurrir que subpoblaciones de células pequeñas no se puedan distinguir de las gotas vacías. Algunas bibliotecas producen múltiples flexiones tipo “rodilla” para múltiples subpoblaciones. El método emptyDrops se ha convertido en una forma popular de lidiar con este problema. EmptyDrops retiene los códigos de barras con conteos altos, pero también añade los códigos de barras que pueden ser estadísticamente diferenciados de los perfiles ambientales, incluso si los conteos totales son similares. Para que podamos ejecutar emptyDrops (o cualquier herramienta de tu elección que logre aplicar umbrales biológicamente relevantes), primero necesitamos volver a ejecutar Alevin, pero previniendo que este aplique sus propios umbrales, ya que no son los óptimos.
Para poder utilizar emptyDrops de manera efectiva, necesitamos regresar y volver a ejecutar Alevin previniendo que aplique sus propios umbrales. Haz click sobre el icono de ‘volver a ejecutar’ en cualquier salida de Alevin dentro de tu historial ya que casi todos los parámetros son los mismos que antes, con la excepción de que necesitas cambiar los valores siguientes:
Generar una matriz sin procesamiento en un formato utilizable
Práctica: Práctica: Prevenir que Alevin utilice sus propios umbrales
- Alevin Tool: toolshed.g2.bx.psu.edu/repos/bgruening/alevin/alevin/1.3.0+galaxy2 (Haz clic sobre la última salida de Alevin para volver a ejecutar)
- “Optional commands”
- “keepCBFraction”: ‘1’ - por ejemplo conservarlos todos
- “freqThreshold”: ‘3’ - Esto solo eliminará los códigos de barras celulares que tengan una frecuencia menor de 3, un criterio bajo de aceptación, pero es una forma útil de evitar procesar un monton de códigos de barras que es casi seguro que estan vacíos.
- Expande uno de los conjuntos de datos de la salida de la herramienta haciendo clic sobre él
- Selecciona volver a ejecutar galaxy-refresh de la herramienta
Esto es de utilidad si quieres volver a correr la herramienta variando ligeramente los valores de los parámetros, o si deseas verificar la configuración de parámetros que utilizaste.
Preguntas: Pregunta¿Cuántas células hay ahora en la salida?
- ¡Ahora hay
22539células en quants_mat_rows! Muchas más que las2163que Alevin filtró. ¡Esto necesita ser filtrado en serio con emptyDrops!
Alevin da salida a un formato MTX, el cual puede ser la entrada del paquete dropletUtils y procesarse en emptyDrops. Desafortunadamente la matriz tiene una orientación equivocada. La matriz no puede ser procesada por herramientas cuya entrada son archivos como los que produce el software 10X. Necesitamos ‘transformar’ la matriz de tal forma que las células esten en columnas y los genes en filas.
Aviso: ¡Precaucion!¡No mezcles los archivos de distintas ejecuciones de Alevin! Utiliza la última ejecución, la cual tiene los números más altos en el historial.
Práctica: Práctica: Transformación de la matriz
- salmonKallistoMtxTo10x Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/salmon_kallisto_mtx_to_10x/_salmon_kallisto_mtx_to_10x/0.0.1+galaxy5 con los siguientes parámetros:
- param-file “.mtx-format matrix”:
quants_mat.mtx.gz(la salida de la herramienta Alevin tool)- param-file “Tab-delimited genes file”:
quants_mat_cols.txt(la salida de la herramienta Alevin tool)- param-file “Tab-delimited barcodes file”:
quants_mat_rows.txt(la salida de la herramienta Alevin tool)- Cambiar el nombre galaxy-pencil de ‘salmonKallistoMtxTo10x….:genes’ a
Gene table- Cambiar el nombre galaxy-pencil de ‘salmonKallistoMtxTo10x….:barcodes’ a
Barcode table- Cambiar el nombre galaxy-pencil de ‘salmonKallistoMtxTo10x….:matrix’ a
Matrix table
La salida es una matriz que contendrá la orientación correcta para poder ser utilizada por las herramientas en el análisis subsecuente. Sin embargo, nuestra matriz se ve un poco dispersa, por ejemplo, haz clic en Gene table. No se tú, pero a mí me costaría entablar una buena discusión biológica utilizando únicamente los gene_ids de Ensembl. Lo que en realidad me gustaría es tener información más ‘humanamente entendible’, como la del tipo ‘GAPDH’ o con otro tipo de acrónimos de genes; también me gustaría tener información sobre genes mitocondriales para poder evaluar si mis células están bajo algún tipo de estrés o no. Con el objetivo de preparar nuestros datos para meterlos a emptyDrops, vamos a combinar esta información y depositarla en un objeto; ahora es más sencillo añadir dicha información.
Añadir metadatos de genes
Preguntas: Pregunta¿Dónde podemos encontrar esta información sobre los genes?
Dentro de un archivo GTF, nuestro viejo amigo.
Preguntas: Pregunta¿Cual de los ‘atributos’ dentro de la última columna del archivo contiene el acrónimo de los genes?
gene_name
Ahora vamos a volver a ejecutar la herramienta que extrae información contenida dentro de nuestro archivo GTF.
Práctica: Práctica: Generar información de genes
- GTF2GeneList Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/gtf2gene_list/_ensembl_gtf2gene_list/1.42.1+galaxy6 con los siguientes parámetros:
- “Feature type for which to derive annotation”:
gene- “Field to place first in output table”:
gene_id- “Suppress header line in output?”:
Yes- “Comma-separated list of field names to extract from the GTF (default: use all fields)”:
gene_id,gene_name,mito- “Append version to transcript identifiers?”:
Yes- “Flag mitochondrial features?”:
Yes- nota, esto va a rellenar automáticamente campos con un montón de genes asociados a la mitocondria (que se encontraron en el archivo GTF). ¡Esto es bueno!- “Filter a FASTA-format cDNA file to match annotations?”:
No- - no lo necesitamos, ¡hemos terminado con nuestro archivo FASTA!- Verifica que el archivo de salida sea del tipo
tabular. Si no lo es, cambia el tipo de archivo haciendo click sobre ‘Editar atributos’galaxy-pencil que está en el historial del conjunto de datos (como si estuvieras cambiando el nombre al archivo). Después haz click sobreDatatypesy tecleatabular. Haz clic sobreChange datatype.)- Cambiar el nombre galaxy-pencil de la tabla de anotación a
Gene Information
Inspecciona galaxy-eye el objeto Gene Information del historial. Ahora has incluido un nuevo campo para gene_id, esto incluye el nombre de los genes y una columna para información mitocondrial (false = not mitochondrial, true = mitochondrial). Necesitamos añadir esta información a la tabla de salida ‘Gene table’ proveniente de la herramienta salmonKallistoMtxto10x. Sin embargo, necesitamos mantener la tabla ‘Gene table’ en el mismo orden, ya que se hace referencia a ella en las filas de la tabla ‘Matrix table’.
Práctica: Práctica: Combinar la tabla de genes MTX con la información de los genes
- Join two Datasets Tool: join1 con los siguientes parámetros:
- “Join”:
Gene Table- “Using column”:
Column: 1- “with”:
Gene Information- “and column”:
Column: 1- “Keep lines of first input that do not join with second input”:
Yes- “Keep lines of first input that are incomplete”:
Yes- “Fill empty columns”:
No- “Keep the header lines”:
NoSi inspeccionas galaxy-eye el objeto, verás que hemos unido estas tablas y que ahora tiene algunos pocos gene_id repetidos. Eliminemos estas repeticiones manteniendo a su vez el orden original de la tabla ‘Gene Table’.
- Cut columns from a table Tool: Cut1 con los siguientes parámetros:
- “Cut columns”:
c1,c4,c5- “Delimited by”:
Tab- “From”: la salida de la herramienta Join two Datasets tool
- Cambiar el nombre galaxy-pencil de la salida a
Annotated Gene Table
Inspecciona galaxy-eye tu tabla Annotated Gene Table. ¡Esto es más parecido a lo que buscamos! Tenemos gene_id, gene_name, y mito. ¡Ahora regresemos a nuestro trayecto inicial con rumbo hacia emptyDrops y su forma sofisticada de utilizar umbrales para detectar gotas vacías!
emptyDrops
La herramienta emptyDrops Lun et al. 2019 trabaja con un tipo específico de objeto R llamado SingleCellExperiment. Necesitamos convertir nuestros archivos transformados MTX a este tipo de objetos, esto lo haremos utilizando la herramienta Read10x de DropletUtils:
Práctica: Práctica: Convertir al formato SingleCellExperiment
- DropletUtils Read10x Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/dropletutils_read_10x/dropletutils_read_10x/1.0.3+galaxy2 con los siguientes parámetros:
- param-file “Expression matrix in sparse matrix format (.mtx)”:
Matrix table- param-file “Gene Table”:
Annotated Gene Table- param-file “Barcode/cell table”:
Barcode table- “Should metadata file be added?”:
No- Cambiar el nombre galaxy-pencil de salida:
SCE Object
¡Fantástico! Ya hemos convertido la matriz en el objeto que ocupamos, siendo más específicos, la hemos convertido al formato SingleCellExperiment, ¡Ahora podemos ejecutar emptyDrops! Pero primero deshagámonos de esas gotas que no contienen células.
Práctica: Práctica: emptyDrops
- DropletUtils emptyDrops Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/dropletutils_empty_drops/dropletutils_empty_drops/1.0.3+galaxy1 con los siguientes parámetros:
- param-file “SingleCellExperiment rdata object”:
SCE Object- “Should barcodes estimated to have no cells be removed from the output object?”:
YesCambiar el nombre galaxy-pencil de la salida de
serialised SingleCellExperimentaStringent-Object- Cambiar el nombre galaxy-pencil de
tabular outputaStringent-Tabular Output
Preguntas: Pregunta¿Cuántos códigos de barras de células quedan después de procesar emptyDrops? ¿Por qué será esto?
Si haces clic sobre el
Stringent-Objecten el historial galaxy-history, el texto de la ventana dice22 barcodeso algo similar. ¿Por qué es tan bajo? Toma en consideración, ¿Es este un conjunto de datos completo?Recuerda que este conjunto de datos está submestreado. Si observas detenidamente los parámetros de emptyDrops, verás que la herramienta estableció un umbral mínimo de 100 UMI. Analizando los gráficos de códigos de barras mostrados en este tutorial, para la muestra de 400k lecturas, verás que este umbral es demasiado riguroso para la muestra submuestreada. Saliendo de dudas, este umbral mínimo daría como resultado
3011códigos de barras para la muestra total.
Ejecutemos de nuevo y cambiemos parámetros; volvamos a ejecutar la herramienta con un umbral mínimo más laxo.
Si estáis trabajando en equipo en este punto tenéis la oportunidad de tomar diversas rutas, la primera utilizando un control y el resto variando números para que podáis comparar resultados a lo largo de los tutoriales.
- Variable: UMI count lower bound
- Control:
5- Todos los demás: Tomad en consideración los gráficos de rangos de códigos de barras y seleccionad diversos límites inferiores.
Práctica: Práctica: emptyDrops - ¡Intentemoslo de nuevo!
- DropletUtils emptyDrops Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/dropletutils_empty_drops/dropletutils_empty_drops/1.0.3+galaxy1 con los siguiente parámetros:
- param-file “SingleCellExperiment rdata object”:
SCE Object- “UMI count lower bound”:
5- aquí puedes usar diversos valores y ver que sucede- “Should barcodes estimated to have no cells be removed from the output object?”:
YesCambiar el nombre galaxy-pencil de la salida
serialised SingleCellExperimenta<pon tu número aquí>UMI-Object- Cambiar el nombre galaxy-pencil de la salida
tabular outputa<pon tu número aquí>UMI-Tabular Output
¡En este punto debes tener 111 códigos de barras! Ahora tienes una matriz de expresión anotada y lista para los procesos y análisis subsecuentes, ¡Bien hecho! Sin embargo, en los siguientes tutoriales nos vincularemos al uso de una herramienta llamada Scanpy. Por tanto, necesitarás convertir este objeto SingleCellExperiment a un formato llamado annData, el cual es una variante de un archivo que utiliza un formato llamado hdf5.
Práctica: Práctica: Conversión al formato AnnData
- SCEasy convert Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/sceasy_convert/sceasy_convert/0.0.5+galaxy1 con los siguientes parámetros:
- “Direction of conversion”:
SingleCellExperiment to AnnData- param-file “Input object in SingleCellExperiment RDS format”:
<pon tu número aquí>UMI-Object- “Name of the assay to be transferred as main layer”:
counts- Cambiar el nombre galaxy-pencil de la salida a
N701-400k-AnnData
congratulations ¡Felicidades! Tu objeto está listo para el pipeline de Scanpy. Ahora puedes verificar tu trabajo comparándolo con el mostrado en este historial de ejemplo.
Sin embargo, quizá quieras combinar este objeto con otros parecidos a él. Por ejemplo, es posible que hayas procesado 5 muestras, y que hayas empezado a partir de 10 archivos FASTQ…
Combinar archivos FASTQ
Esta muestra es una de siete iniciales. Entonces, puedes utilizar un flujo de trabajo para procesar los otros 12 archivos FASTQ submuestreados. Nota que, por desgracia, la muestra submuestreada N705 contiene mayormente lecturas chatarra; por tanto, emptyDrops no funciona. Debido a esto, yo la procesé con Alevin. Por supuesto, la muestra completa funciona bien con emptyDrops. Va a tomar un buen rato el procesado de todas estas muestras, así que mientras tanto ve por uno, o varios cafecitos… O aún mejor, yo ya procesé las muestras, y las deposité en un nuevo historial para que lo puedas importar y empezar con un historial limpio. Alternativamente, puedes obtener estos datos desde el repositorio Zenodo.
Datos
Práctica: Práctica: Cargar datos - Combinar archivos
- Crear un historial huevo para este tutorial (si es que no estás importando el historial mencionado en la parte superior)
Importar los diversos archivos AnnData y la tabla de diseño experimental desde Zenodo
https://zenodo.org/record/4574153/files/Experimental_Design.tabular https://zenodo.org/record/4574153/files/N701-400k-AnnData.h5ad https://zenodo.org/record/4574153/files/N702-400k-AnnData.h5ad https://zenodo.org/record/4574153/files/N703-400k-AnnData.h5ad https://zenodo.org/record/4574153/files/N704-400k-AnnData.h5ad https://zenodo.org/record/4574153/files/N705-400k-AnnData.h5ad https://zenodo.org/record/4574153/files/N706-400k-AnnData.h5ad https://zenodo.org/record/4574153/files/N707-400k-AnnData.h5ad
- Copia los enlaces
Abre el manejador de carga de datos de Galaxy (galaxy-upload en la parte superior derecha del panel de herramientas)
- Selecciona ‘Pegar/Traer datos’ Paste/Fetch Data
Copia los enlaces en el campo de textos
Presiona ‘Iniciar’ Start
Close Cierra la ventana.
- Galaxy utiliza los URLs como nombres de forma predeterminada , así que los tendrás que cambiar a algunos que sean más útiles o informativos.the window
- Cambiar de nombre al conjunto de datos
Verifica que el tipo de datos sea
h5adde lo contrario ¡Necesitarás cambiar cada tipo de datos al formatoh5ad!
- Selecciona sobre el galaxy-pencil icono del lápiz para editar los atributos del conjunto de datos
- Selecciona en la pestaña galaxy-chart-select-data Datatypes en la parte superior del panel central
- Selecciona
datatypes- Da clic en el botón Change datatype
Inspecciona galaxy-eye el archivo de texto Experimental Design. Este muestra cómo cada N70X corresponde a una muestra, y si dicha muestra proviene de un macho o hembra. Estos serán metadatos importantes para agregar a nuestra muestra, los cuales añadiremos de forma similar a la forma en que añadiste los metadatos gene_name y mito en secciones anteriores.
Concatenación de objetos
Práctica: Práctica: Concatenación de objetos AnnData
- Manipulate AnnData Tool: toolshed.g2.bx.psu.edu/repos/iuc/anndata_manipulate/anndata_manipulate/0.7.5+galaxy0 con los siguientes parámetros:
- param-file “Annotated data matrix”:
N701-400k-AnnData- “Function to manipulate the object”: ‘Concatenate along the observations axis’
- param-file “Annotated data matrix to add”: ‘Select all the other matrix files from bottom to top’
- “Join method”:
Intersection of variables- “Key to add the batch annotation to obs”:
batch- “Separator to join the existing index names with the batch category”:
-
¡Demos un vistazo a lo que hemos hecho! Desafortunadamente, los objetos AnnData son bastante complicados, así que aquí el icono del ojo galaxy-eye no nos será de mucha ayuda. En lugar de esto, de aquí en adelante vamos a utilizar una herramienta para visualizar nuestro objeto.
Práctica: Práctica: Inspección de objetos AnnData
- Inspect AnnData Tool: toolshed.g2.bx.psu.edu/repos/iuc/anndata_inspect/anndata_inspect/0.7.5+galaxy0 con los siguiente parámetros:
- param-file “Annotated data matrix”: la salida de la herramienta Manipulate AnnData tool
- “What to inspect?”:
General information about the object- Inspect AnnData Tool: toolshed.g2.bx.psu.edu/repos/iuc/anndata_inspect/anndata_inspect/0.7.5+galaxy0 con los siguiente parámetros:
- param-file “Annotated data matrix”: la salida de la herramienta Manipulate AnnData tool
- “What to inspect?”:
Key-indexed observations annotation (obs)- Inspect AnnData Tool: toolshed.g2.bx.psu.edu/repos/iuc/anndata_inspect/anndata_inspect/0.7.5+galaxy0 con los siguiente parámetros:
- param-file “Annotated data matrix”: la salida de la herramienta Manipulate AnnData tool
- “What to inspect?”:
Key-indexed annotation of variables/features (var)
Ya hemos visualizado las tres salidas de tool Inspect AnnData.
Preguntas: Preguntas
- ¿Cuántas células tienes ahora?
- ¿Dónde está almacenada la información del lote (
batch)?
- Si verificas la salida General information tool, podrás ver que ahora tienes
4079 células, ya que la matriz ahora tiene 4079 células y 35,734 genes. También puedes observar esto en los tamaños de los archivos obs tool (células) and var tool (genes).- En la anotación de observaciones indexadas por clave Key-indexed observations annotation (obs). Las diferentes versiones de la herramienta ‘Manipulate’ colocarán las columnas del lote (
batch) en diferentes ubicaciones. La versión de la herramienta utilizada en este curso asigna a la novena columna (9) en la posición de más a la derecha, la cual determina el ‘lote’ (batch). Lote (batch) se refiere al orden en que se agregaron las matrices. Los archivos se agregan desde la parte inferior del historial hacia arriba, ¡Así que ten cuidado en cómo configuras tus historiales al ejecutar esto!
Añadir el lote de metadatos (batch metadata)
Configura el historial de ejemplo con los índices más antiguos en la parte inferior.
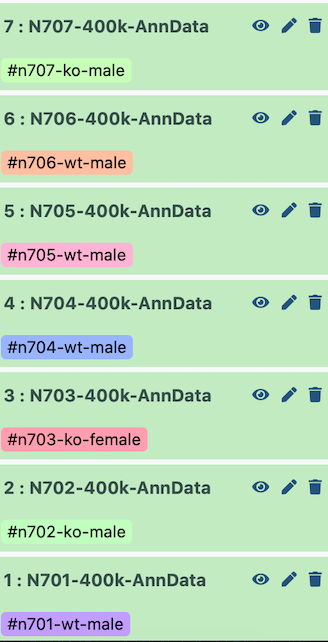
Por tanto, cuando se concatenan, el lote (batch) aparece de la siguiente manera:
| Index | Batch | Genotype | Sex |
|---|---|---|---|
| N701 | 0 | wildtype | male |
| N702 | 1 | knockout | male |
| N703 | 2 | knockout | female |
| N704 | 3 | wildtype | male |
| N705 | 4 | wildtype | male |
| N706 | 5 | wildtype | male |
| N707 | 6 | knockout | male |
Puede ser que los índices no se hayan importado en orden si utilizaste Zenodo para importar tus archivos (por ejemplo, N701 a N707, ascendentes). En ese caso necesitarás manipular de forma apropiada los parámetros de las siguientes herramientas para etiquetar tus lotes correctamente.
Los dos metadatos más críticos en este experimento son sex y genotype. Posteriormente, vamos a colorear nuestros gráficos de células según los valores de estos parámetros, así que vamos a añadirlos ya.
Práctica: Práctica: Etiquetas de sexo
- Replace Text in a specific column Tool: toolshed.g2.bx.psu.edu/repos/bgruening/text_processing/tp_replace_in_column/1.1.3 con los siguientes parámetros:
- param-file “File to process”: la salida de la herramienta Inspect AnnData: Key-indexed observations annotation (obs) tool)
“1. Replacement”
- “in column”:
Column: 9- or whichever columnbatchis in- “Find pattern”:
0|1|3|4|5|6- “Replace with”:
male- + Insert Replacement
“2. Replacement”
- “in column”:
Column: 9- “Find pattern”:
2- “Replace with”:
female- + Insert Replacement
“3. Replacement”
- “in column”:
Column: 9- “Find pattern”:
batch- “Replace with”:
sexAhora queremos únicamente la columna que contiene la información de sexo - al final agregaremos esto en la anotación celular del objeto AnnData
- Cut columns from a table Tool: Cut1 con los siguientes parámetros:
- “Cut columns”:
c9- “Delimited by”:
Tab- % icon param-file %} “From”: la salida de la herramienta Replace text tool
- Cambiar el nombre galaxy-pencil de la salida a
Sex metadata
Estuvo divertido, ahora hagámoslo de nuevo pero para el genotipo.
Práctica: Práctica: Etiquetas de genotipo
- Replace Text in a specific column Tool: toolshed.g2.bx.psu.edu/repos/bgruening/text_processing/tp_replace_in_column/1.1.3 con los siguientes parámetros:
- param-file “File to process”: la salida de la herramienta Inspect AnnData: Key-indexed observations annotation (obs) tool
“1. Replacement”
- “in column”:
Column: 9- “Find pattern”:
0|3|4|5- “Replace with”:
wildtype- + Insert Replacement
“2. Replacement”
- “in column”:
Column: 9- “Find pattern”:
1|2|6- “Replace with”:
knockout- + Insert Replacement
“3. Replacement”
- “in column”:
Column: 9- “Find pattern”:
batch- “Replace with”:
genotypeAhora queremos únicamente la columna que contiene la información de genotipo - al final agregaremos esto en la anotación celular del objeto AnnData.
- Cut columns from a table Tool: Cut1 con los siguientes parámetros:
- “Cut columns”:
c9- “Delimited by”:
Tab- param-file “From”: la salida de la herramienta Replace text tool
- Cambiar el nombre galaxy-pencil de la salida a
Genotype metadata
Es posible que desees hacer esto con distintos tipos de metadatos - qué laboratorios manejaron las muestras, en qué día se procesaron, etc. Una vez que hayas agregado todas tus columnas de metadatos, podemos entonces adherirlas unas a otras antes de conectarlas al objeto AnnData.
Práctica: Práctica: Combinar las columnas de metadatos
- Paste two files side by side Tool: Paste1 con los siguientes parámetros:
- param-file “Paste”:
Genotype metadata- param-file “and”:
Sex metadata- “Delimit by”:
Tab- Cambiar el nombre galaxy-pencil de la salida a
Cell Metadata
¡Agrégalo al objeto AnnData!
Práctica: Práctica: Añadir los metadatos al objeto AnnData
- Manipulate AnnData Tool: toolshed.g2.bx.psu.edu/repos/iuc/anndata_manipulate/anndata_manipulate/0.7.5+galaxy0 con los siguientes parámetros:
- param-file “Annotated data matrix”: la salida de la herramienta Manipulate AnnData tool
- “Function to manipulate the object”:
Add new annotation(s) for observations or variables- “What to annotate?”:
Observations (obs)`- param-file “Table with new annotations”:
Cell Metadata
¡Perfecto! Ahora puedes ejecutar Inspect AnnData para verificación, pero primero limpiemos un poco más este objeto. Sería mucho mejor si “lote” (batch) significara algo, en lugar de “el orden en el que la herramienta ‘Manipulate AnnData’ agregó mis conjuntos de datos”.
Práctica: Práctica: Etiquetado de lotes
- Manipulate AnnData Tool: toolshed.g2.bx.psu.edu/repos/iuc/anndata_manipulate/anndata_manipulate/0.7.5+galaxy0 con los siguientes parámetros:
- param-file “Annotated data matrix”: la salida de la herramienta Manipulate AnnData - Add new annotations tool
- “Function to manipulate the object”:
Rename categories of annotation- “Key for observations or variables annotation”:
batch- “Comma-separated list of new categories”:
N701,N702,N703,N704,N705,N706,N707
¡Ya casi llegamos a donde queremos! Sin embargo, mientras que nos hemos enfocado en los metadatos de nuestras células (muestra, lote, genotipo, etc.) para etiquetar las ‘observaciones’ en nuestro objeto…
Lecturas mitocondriales
¿Recuerdas cuando mencionamos mitocondrias en los inicios de este tutorial? Y en muestras de células únicas, ¿Cómo de frecuente el ARN mitocondrial es un indicador de estrés durante la disociación? Probablemente deberíamos hacer algo con nuestra columna de verdadero/falso (true/false) en la anotación de genes, la cual nos provee información sobre las células. Ya sea que hayas combinado los archivos FASTQ o que estés analizando solo un archivo necesitarás hacer esto (saltándose así las secciones 4 y 5).
Práctica: Práctica: Calculando el ARN mitocondrial en las células
- AnnData Operations Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/anndata_ops/anndata_ops/0.0.3+galaxy1 con los siguientes parámetros:
- param-file “Input object in hdf5 AnnData format”: la salida de la herramienta Manipulate AnnData - Rename categories tool
- “Format of output object”:
AnnData format- “Copy AnnData to .raw”:
No- “Gene symbols field in AnnData”:
NA.- “Flag genes that start with these names”:
Insert Flag genes that start with these names- “Starts with”:
True- “Var name”:
mito- “Number of top genes”:
50
congratulations ¡Bien hecho! Te sugiero encarecidamente que juegues un poco e inspecciones tu objeto Inspect AnnData tool final preprocesado de AnnData (Pre-processed object) para que puedas ver la gran cantidad de información que ha sido agregada. ¡Ya está todo listo para continuar con el filtrado! Sin embargo, hay un truco que puede ahorrarte tiempo en el futuro…
Extraer datos de secuenciación de ARN de células únicas desde bases de datos públicas
Si te interesa analizar datos de acceso público, particularmente del Single Cell Expression Atlas, quizá te interese la herramienta Moreno et al. 2020, la cual más bien reduce estos pasos en uno. Aquí puedes encontrar el conjunto de datos para este tutorial, el cual tiene el número de identificación de experimento E-MTAB-6945.
Práctica: Práctica: Obtener datos de el Atlas de Expresión de Células Únicas
- EBI SCXA Data Retrieval Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/retrieve_scxa/retrieve_scxa/v0.0.2+galaxy2 con los siguientes parámetros:
- “SC-Atlas experiment accession”:
E-MTAB-6945- “Choose the type of matrix to download”:
Raw filtered countsAhora necesitamos transformar estos datos en un objeto tipo AnnData
- Scanpy Read10x Tool: toolshed.g2.bx.psu.edu/repos/ebi-gxa/scanpy_read_10x/scanpy_read_10x/1.6.0+galaxy0 con los siguientes parámetros:
- “Expression matrix in sparse matrix format (.mtx)”:
EBI SCXA Data Retrieval on E-MTAB-6945 matrix.mtx (Raw filtered counts)- “Gene table”:
EBI SCXA Data Retrieval on E-MTAB-6945 genes.tsv (Raw filtered counts)- “Barcode/cell table”:
EBI SCXA Data Retrieval on E-MTAB-6945 barcodes.tsv (Raw filtered counts)- “Cell metadata table”:
EBI SCXA Data Retrieval on E-MTAB-6945 exp_design.tsv
Es importante tener en cuenta que esta matriz es procesada de cierto modo por medio del pipeline SCXA, que es muy similar a este tutorial, y que contiene todos y cada uno de los metadatos proporcionados por su pipeline, así como sus autores (por ejemplo, más anotaciones celulares o de genes).
Conclusion
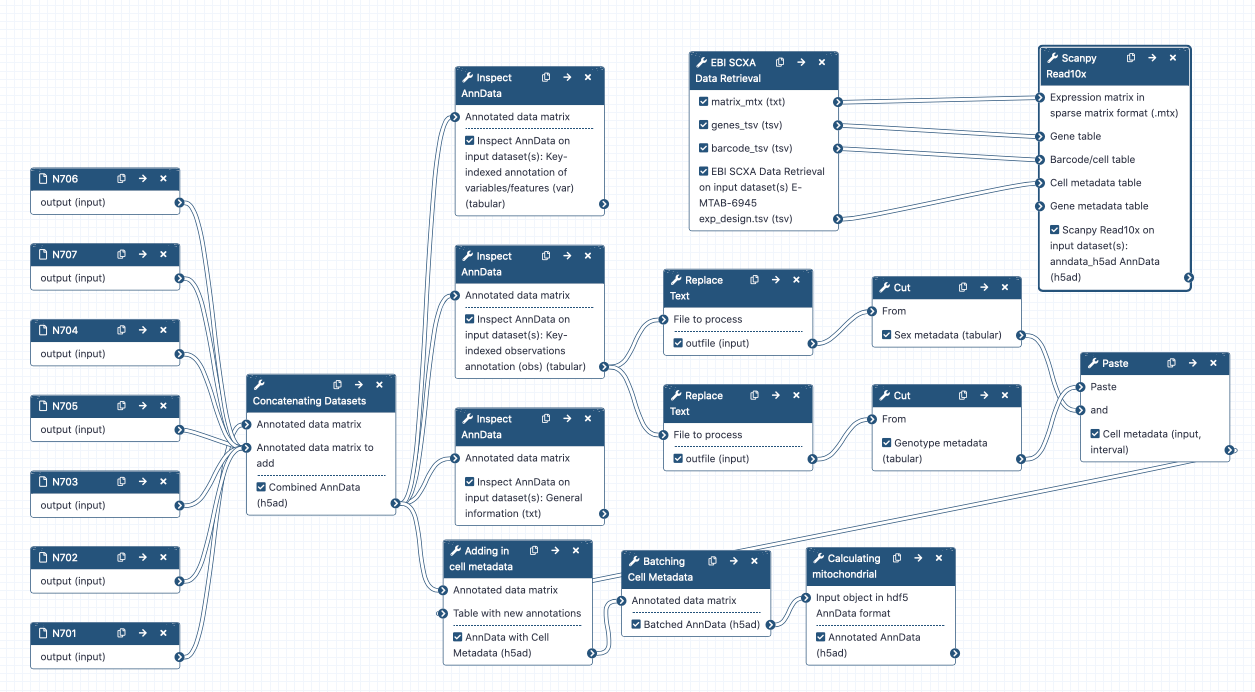
¡Has llegado al final de esta sesión! Quizá te interese echarle un vistazo a un ejemplo de un historial y a la Parte 2 del flujo de trabajo. Nota que según la forma en que ejecutes el flujo de trabajo este requerirá que cambies la columna (column) que contiene el lote de metadatos. Aquí puedes encontrar el objeto final que contiene todas las lecturas.
Hemos:
- Tomado lecturas crudas, anotaciones y los archivos de entrada necesarios para cuantificación.
- Ejecutado Alevin con dos distintas configuraciones de parámetros, ambas permitiendo que la herramienta tome sus propias decisiones sobre qué es lo que constituyen las gotas vacías y, hemos aplicado emptyDrops en su lugar.
- Desplegado gráficos de rangos de códigos de barras para valorar de manera rápida las señales presentes en los conjuntos de datos generados por técnicas de goteo.
- Aplicado las conversiones necesarias para pasar estos datos a los procesos subsecuentes.
- Obtenido datos con análisis parciales desde el Single Cell Expression Atlas.
¡Únete a nuestro canal de Gitter de secuenciación de ARN de células únicas para tomar parte en discusiones con científicos con ideas afines a las tuyas! 
Puntos clave
Partiendo de archivos FASTQ crear un objeto AnnData que sea accesible con scanpy, incluir metadatos relevantes sobre células y genes
Combinar múltiples muestras y etiquetar según el diseño del estudio
Preguntas frecuentes
Have questions about this tutorial? Check out the tutorial FAQ page or the FAQ page for the Transcriptomics topic to see if your question is listed there. If not, please ask your question on the GTN Gitter Channel or the Galaxy Help ForumUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Referencias
- Bacon, W. A., R. S. Hamilton, Z. Yu, J. Kieckbusch, D. Hawkes et al., 2018 Single-Cell Analysis Identifies Thymic Maturation Delay in Growth-Restricted Neonatal Mice. Frontiers in Immunology 9: 10.3389/fimmu.2018.02523
- Lun, A., S. Riesenfeld, T. Andrews, T. Dao, T. Gomes et al., 2019 EmptyDrops: Distinguishing cells from empty droplets in droplet-based single-cell RNA sequencing data. Genome Biology 20: 63. 10.1186/s13059-019-1662-y
- Srivastava, A., L. Malik, T. Smith, I. Sudbery, and R. Patro, 2019 Alevin efficiently estimates accurate gene abundances from dscRNA-seq data. Genome Biology 20: 10.1186/s13059-019-1670-y
- Moreno, P., N. Huang, J. R. Manning, S. Mohammed, A. Solovyev et al., 2020 User-friendly, scalable tools and workflows for single-cell analysis. bioRxiv. 10.1101/2020.04.08.032698 https://www.biorxiv.org/content/early/2020/04/09/2020.04.08.032698
Retroalimentación
¿Utilizaste este material como instructor? Cuéntanos tu experiencia.
¿Has usado este material como aprendiz o estudiante? Haz click en el formulario a continuación para dejarnos tu opinión

Cómo citar este tutorial
- Wendi Bacon, Jonathan Manning, Patricia Carvajal López, Alejandra Escobar-Zepeda, 2022 Generación de una matriz de datos de secuenciación de ARN de células únicas utilizando Alevin (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/transcriptomics/tutorials/scrna-case_alevin/tutorial_ES.html Online; accessed TODAY
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
¡Felicitaciones! ¡Completaste con éxito este tutorial!@misc{transcriptomics-scrna-case_alevin, author = "Wendi Bacon and Jonathan Manning and Patricia Carvajal López and Alejandra Escobar-Zepeda", title = "Generación de una matriz de datos de secuenciación de ARN de células únicas utilizando Alevin (Galaxy Training Materials)", year = "2022", month = "09", day = "28" url = "\url{https://training.galaxyproject.org/training-material/topics/transcriptomics/tutorials/scrna-case_alevin/tutorial_ES.html}", note = "[Online; accessed TODAY]" } @article{Batut_2018, doi = {10.1016/j.cels.2018.05.012}, url = {https://doi.org/10.1016%2Fj.cels.2018.05.012}, year = 2018, month = {jun}, publisher = {Elsevier {BV}}, volume = {6}, number = {6}, pages = {752--758.e1}, author = {B{\'{e}}r{\'{e}}nice Batut and Saskia Hiltemann and Andrea Bagnacani and Dannon Baker and Vivek Bhardwaj and Clemens Blank and Anthony Bretaudeau and Loraine Brillet-Gu{\'{e}}guen and Martin {\v{C}}ech and John Chilton and Dave Clements and Olivia Doppelt-Azeroual and Anika Erxleben and Mallory Ann Freeberg and Simon Gladman and Youri Hoogstrate and Hans-Rudolf Hotz and Torsten Houwaart and Pratik Jagtap and Delphine Larivi{\`{e}}re and Gildas Le Corguill{\'{e}} and Thomas Manke and Fabien Mareuil and Fidel Ram{\'{\i}}rez and Devon Ryan and Florian Christoph Sigloch and Nicola Soranzo and Joachim Wolff and Pavankumar Videm and Markus Wolfien and Aisanjiang Wubuli and Dilmurat Yusuf and James Taylor and Rolf Backofen and Anton Nekrutenko and Björn Grüning}, title = {Community-Driven Data Analysis Training for Biology}, journal = {Cell Systems} }