Classification in Machine Learning

 Alireza Khanteymoori
Alireza Khanteymoori Anup Kumar
Anup Kumar Simon Bray
Simon BrayOverviewQuestions:Objectives:
What is classification and how we can use classification techniques?
Requirements:
Learn classification background
Learn what a quantitative structure-analysis relationship (QSAR) model is and how it can be constructed in Galaxy
Learn to apply logistic regression, k-nearest neighbors, support verctor machines, random forests and bagging algorithms
Learn how visualizations can be used to analyze the classification results
Time estimation: 2 hoursSupporting Materials:Last modification: Oct 18, 2022
 Questions:
Questions:
Introduction
In this tutorial you will learn how to apply Galaxy tools to solve classification problems. First, we will introduce classification briefly, and then examine logistic regression, which is an example of a linear classifier. Next, we will discuss the nearest neighbor classifier, which is a simple but nonlinear classifier. Then advanced classifiers, such as support vector machines, random forest and ensemble classifiers will be introduced and applied. Furthermore, we will show how to visualize the results in each step.
Finally, we will discuss how to train the classifiers by finding the values of their parameters that minimize a cost function. We will work through a real problem in the field of cheminformatics to learn how the classifiers and learning algorithms work.
Classification is a supervised learning method in machine learning and the algorithm which is used for this learning task is called a classifier. In this tutorial we will build a classifier which can predict whether a chemical substance is biodegradable or not. Substances which degrade quickly are preferable to those which degrade slowly, as they do not accumulate and pose a risk to the environment. Therefore, it is useful to be able to predict easily in advance whether a substance is biodegradable prior to production and usage in consumer products.
AgendaIn this tutorial, we will cover:
Classification
Classification is the process of assigning every object from a collection to exactly one class from a known set of classes by learning a “decision boundary” in a dataset. This dataset is called a training dataset and contains multiple samples, together with a desired class for each sample. The training dataset contains “features” as columns and a mapping between these features and the class label is learned for each sample.
The performance of mapping is evaluated using a test dataset, which is separate from the training dataset. The test dataset contains only the feature columns, but not the class column. The class column is predicted using the mapping learned on the training dataset. An example of a classification task is assigning a patient (the object) to a group of healthy or ill (the classes) people on the basis of his or her medical record. In this tutorial, we will use a classifier to train a model using a training dataset, predict the targets for test dataset and visualize the results using plots.
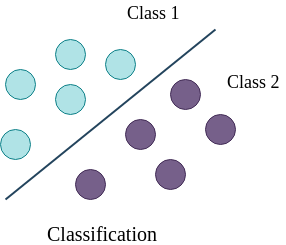
In figure 1, the line is a boundary which separates a class from another class (for example from tumor to no tumor). The task of a classifier is to learn this boundary, which can be used to classify or categorize an unseen/new sample. The line is the decision boundary; there are different ways to learn it, which correspond to different classification algorithms. If the dataset is linearly separable, linear classifiers can produce good classification results. However, when the dataset is complex and requires non-linear decision boundaries, more powerful classifiers like support vector machine or ensemble based classifiers may prove to be beneficial.
The data classification process includes two steps:
-
Building the classifier or model: This step is the learning step, in which the classification algorithms build the classifier. The classifier is built from the training set made up of database samples and their associated class labels. Each sample that constitutes the training set is referred to as a class.
-
Applying the classifier to a classification task: In this step, the classifier is used for classification. Here the test data is used to estimate the accuracy of classification rules. The classification rules can be applied to the new data samples if the accuracy is considered acceptable.
Quantitative structure - activity relationship biodegradation
The classification problem we will study in this tutorial is related to biodegradation. Chemical substances which decay slowly will accumulate over time, which poses a threat to the environment. Therefore, it is useful to be able to predict in advance whether a substance will break down quickly or not.
Quantitative structure-activity relationship (QSAR) and quantitative structure-property relationship (QSPR) models attempt to predict the activity or property of chemicals based on their chemical structure. To achieve this, a database of compounds is collected for which the property of interest is known. For each compound, molecular descriptors are collected which describe the structure (for example: molecular weight, number of nitrogen atoms, number of carbon-carbon double bonds). Using these descriptors, a model is constructed which is capable of predicting the property of interest for a new, unknown molecule. In this tutorial we will use a database assembled from experimental data of the Japanese Ministry of International Trade and Industry to create a classification model for biodegradation. We then will be able to use this model to classify new molecules into one of two classes: biodegradable or non-biodegradable.
As a benchmark, we will use the dataset assembled by Mansouri et al. using data from the National Institute of Technology and Evaluation of Japan. This database contains 1055 molecules, together with precalculated molecular descriptors.
In this tutorial, we will apply a couple of scikit-learn machine learning tools to the dataset provided by Mansouri et al. to predict whether a molecule is biodegradable or not. In the following part, we will perform classification on the biodegradability dataset using a linear classifier and then will create some plots to analyze the results.
Get train and test datasets
We have two datasets available; the training dataset contains 837 molecules, while the test dataset contains 218 molecules.
Let’s begin by uploading the necessary datasets.
Hands-on: Data upload
- Create a new history for this tutorial
Import the files from Zenodo
https://zenodo.org/record/3738729/files/train_rows.csv https://zenodo.org/record/3738729/files/test_rows_labels.csv https://zenodo.org/record/3738729/files/test_rows.csv
- Copy the link location
Open the Galaxy Upload Manager (galaxy-upload on the top-right of the tool panel)
- Select Paste/Fetch Data
Paste the link into the text field
Press Start
- Close the window
Rename the datasets as
train_rows,test_rows_labelsandtest_rowsrespectively.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
The train_rows contains a column Class which is the class label or target. We will evaluate our model on test_rows and compare the predicted class with the true class value in test_rows_labels
Preparing the data involves these following major tasks:
- Data cleaning: involves removing noise and treatment of missing values. The noise is removed by applying noise filtering techniques and the problem of missing values is solved by replacing a missing value with different techniques, for example substitution, mean imputation and regression imputation.
- Relevance analysis: the database may also have attributes which are irrelevant for classification. Correlation analysis is used to know whether any two given attributes are related - e.g. one of the features and the target variable.
- Normalization: the data is transformed using normalization. Normalization involves scaling all values for q given attribute in order to make them fall within a small specified range. Normalization is used when in the learning step, neural networks or the methods involving measurements are used.
Learn the logistic regression classifier
As the first step, to learn the mapping between several features and the classes, we will apply the linear classifier. It learns features from the training dataset and maps all the rows to their respective class. The process of mapping gives a trained model. Logistic regression is named for the function used at the core of the method, the logistic function, and it is an instance of supervised classification in which we know the correct label of the class for each sample and the algorithm estimate of the true class. We want to learn parameters (weight and bias for the line) that make the estimated class for each training observation as close as possible to the true class label. This requires two components; the first is a metric for how close the current class label is to the true label. Rather than measure similarity, we usually talk about the opposite of this, the distance between the classifier output and the desired output, and we call this distance, the loss function or the cost function.
The second thing we need is an optimization algorithm for iteratively updating the weights so as to minimize this loss function. The standard algorithm for this is gradient descent. So, the dataset is divided into two parts - training and test sets. The training set is used to train a classifier and the test set is used to evaluate the performance of the trained model.
Hands-on: Train logistic regression classifier
- Generalized linear models tool with the following parameters to train the regressor:
- “Select a Classification Task”:
Train a model
- “Select a linear method”:
Logistic Regression
- “Select input type”:
tabular data
- param-file “Training samples dataset”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
All columns EXCLUDING some by column header name(s)
- param-text “Type header name(s)”:
Class- param-file “Dataset containing class labels”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
Select columns by column header name(s)
- param-text “Select target column(s)”:
Class- Rename the generated file to
LogisticRegression_model
QuestionWhat is learned by the logistic regression model?
In the logistic regressoion model, the coefficients of the logistic regression algorithm have be estimated from our training data. This is done using maximum-likelihood estimation.
Predict class using test dataset
After learning on the training dataset, we should evaluate the performance on the test dataset to know whether the learning algorithm learned a good classifier from the training dataset or not. This classifier is used to predict a new sample and a similar accuracy is expected.
Now, we will predict the class in the test dataset using this classifier in order to see if it has learned important features which can be generalized on a new dataset. The test dataset (test_rows) contains the same number of features but does not contain the Class column. This is predicted using the trained classifier.
Hands-on: Predict class using the logistic regression classifier
- Generalized linear models tool with the following parameters to predict targets of test dataset using the trained model:
- “Select a Classification Task”:
Load a model and predict
- param-file “Models”:
LogisticRegression_model- param-file “Data (tabular)”:
test_rows- param-check “Does the dataset contain header”:
Yes- param-select “Select the type of prediction”:
Predict class labels- Rename the generated file to
LogisticRegression_result
Visualize the logistic regression classification results
We will evaluate the classification by comparing the predicted with the expected classes. In the previous step, we classified the test dataset (LogisticRegression_result). We have one more dataset (test_rows_labels) which contains the true class label of the test set. Using the true and predicted class labels in the test set, we will verify the performance by analyzing the plots. As you can see, LogisticRegression_result has no header, so first we should remove the header from test_rows_labels to compare.
Hands-on: Remove the header
- Remove beginning tool with the following parameters:
- param-file “Remove first”:
1- param-file “from”:
test_rows_labels- Rename the generated file to
test_rows_labels_noheader
Now we visualize and analyze the classification using the “Plot confusion matrix, precision, recall and ROC and AUC curves” tool.
Hands-on: Check and visualize the classification
- Plot confusion matrix, precision, recall and ROC and AUC curves tool with the following parameters to visualize the classification:
- param-file “Select input data file”:
test_rows_labels_noheader- param-file “Select predicted data file”:
LogisticRegression_result- param-file “Select trained model”:
LogisticRegression_model
The visualization tool creates the following plots:
-
Confusion matrix: The confusion matrix summarizes the classification performance of a classifier with respect to the test data. It is a two-dimensional matrix; the horizontal axis (x-axis) shows the predicted labels and the vertical axis (y-axis) shows the true labels. Each rectangular box shows a count of samples falling into the four output combinations (true class, predicted class) - (1, 0), (1, 1), (0, 1) and (0, 0). In Figure 2, the confusion matrix of the predictions is a colour-coded heatmap. For a good prediction, the diagonal running from top-left to bottom-right should contain a smaller number of samples, because it shows the counts of incorrectly predicted samples. Hovering over each box in Galaxy shows the true and predicted class labels and the count of samples.
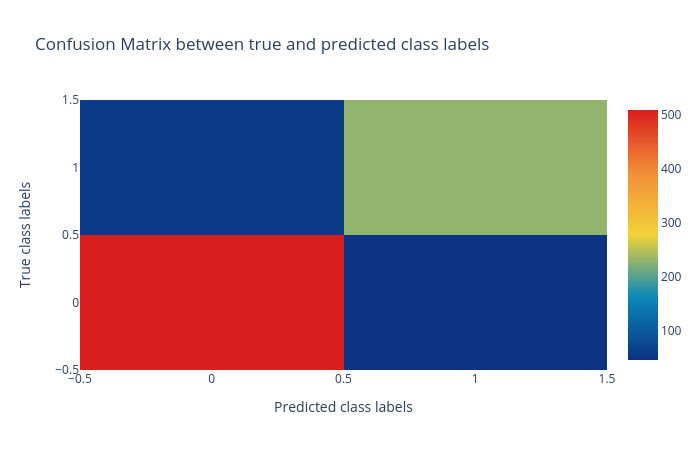
Figure 2: Confusion matrix for the logistic regression classifier. -
Precision, recall and F1 score: Precision, recall and F1 score. These scores determine the robustness of classification. It is important to analyze the plot for any classification task to verify the accuracy across different classes which provides more information about the balanced or imbalanced accuracy across multiple classes present in the dataset.
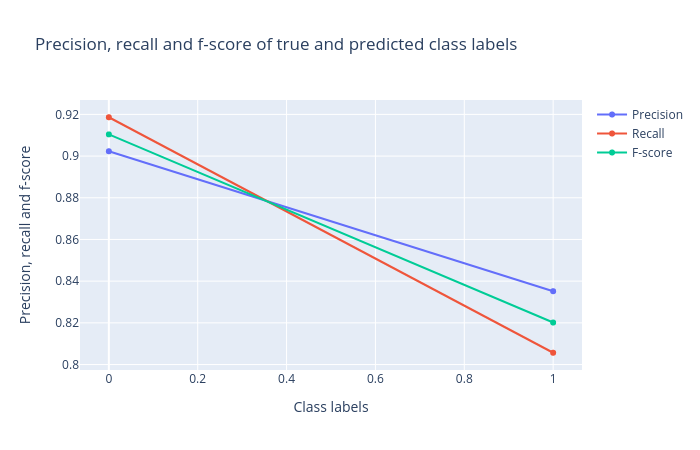
Figure 3: Precision, recall and F1 score for the logistic regression classifier. -
Receiver operator characteristics (ROC) and area under ROC (AUC): Receiver operator characteristics (ROC) and area under ROC (AUC). The ROC curve is shown in blue. For a good prediction, it should be more towards the top-left of this plot, which results in a high AUC value. For a bad prediction, it is close to the orange line (y = x), resulting in a low AUC value (closer to 0.5). An AUC value of exactly 0.5 means the prediction is doing no better than a random number generator at predicting the classes.
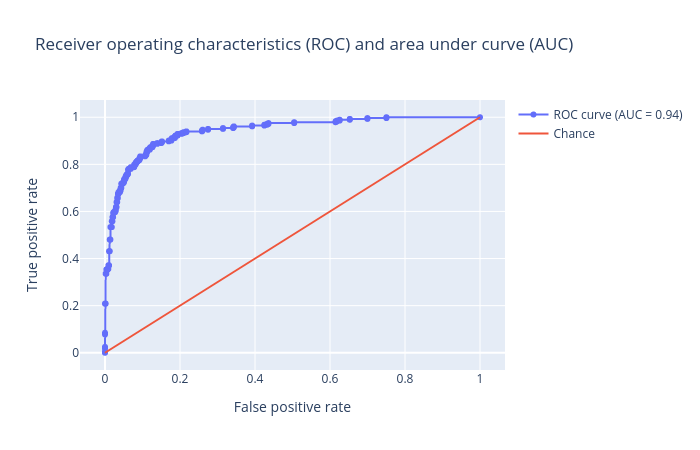
Figure 4: Receiver operator characteristics (ROC) and area under ROC (AUC) for the logistic regression classifier.
These plots are important to visualize the quality of the classifier and the true and predicted classes.
QuestionInspect the plots. What can you say about the classification?
Figures 2,3 and 4 show that the classification is acceptable, but as you will see in the next steps, the results can be improved.
K-Nearest Neighbor (KNN)
At the second step, we will use k-nearest neighbor classifier. In the k-nearest neighbor classifier, a sample is classified by a majority vote of its neighbors. The sample is assigned to the class which is most common among its k nearest neighbors. k is a positive integer and typically it is small. For example, if k = 1, then the sample is simply assigned to the class of that single nearest neighbor. Surprisingly, when the number of data points is large, this classifier is not that bad. Choosing the best value of k is very important. If k is too small, the classifier will be sensitive to noise points and if k is too large, the neighborhood may include points from other classes and causes errors. To select the k that is right for your data, we recommend running the KNN algorithm several times with different values of k and choosing the k that reduces the number of errors the most.
QuestionWhat are advantages and disadvantages about this model?
Advantages:
It is a very simple algorithm to understand and interpret.
It is very useful for nonlinear data because there is no assumption of linearity in this algorithm.
It is a versatile algorithm, as we can use it for classification as well as regression.
It has relatively high accuracy, but there are much better supervised learning models than KNN.
It works very well in low dimensions for complex decision surfaces.
Disadvantages:
Classification is slow, because it stores all the training data.
High memory storage required as compared to other supervised learning algorithms.
Prediction is slow in case of big training samples.
It is very sensitive to the scale of data as well as irrelevant features.
It suffers a lot from the curse of dimensionality.
Hands-on: Train k-nearest neighbor classifier
- Nearest Neighbors Classification tool with the following parameters to train the regressor:
- “Select a Classification Task”:
Train a model
- “Classifier type”:
Nearest Neighbors
- “Select input type”:
tabular data
- param-file “Training samples dataset”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
All columns EXCLUDING some by column header name(s)
- param-text “Type header name(s)”:
Class- param-file “Dataset containing class labels”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
Select columns by column header name(s)
- param-text “Select target column(s)”:
Class- param-select “Neighbor selection method”:
k-nearest neighbors- Rename the generated file to
NearestNeighbors_model
QuestionWhat is the value of k (number of neighbors) for the model?
As you can see in the Advanced Options, the default value for the number of neighbors is 5, and we used the default value. You can set this parameter based on your problem and data.
Now, we should evaluate the performance on the test dataset to find out whether the KNN classifier is a good model from the training dataset or not.
Hands-on: Predict class using the k-nearest neighbor classifier
- Nearest Neighbors Classification tool with the following parameters to predict targets of test dataset using the trained model:
- “Select a Classification Task”:
Load a model and predict
- param-file “Models”:
NearestNeighbors_model- param-file “Data (tabular)”:
test_rows- param-check “Does the dataset contain header”:
Yes- param-select “Select the type of prediction”:
Predict class labels- Rename the generated file to
NearestNeighbors_result
Now we visualize and analyze the classification. As you can see, NearestNeighbors_result has a header, so use test_rows_labels to compare.
Hands-on: Check and visualize the classification
- Plot confusion matrix, precision, recall and ROC and AUC curves tool with the following parameters to visualize the classification:
- param-file “Select input data file”:
test_rows_labels- param-file “Select predicted data file”:
NearestNeighbors_result- param-file “Select trained model”:
NearestNeighbors_model
The visualization tool creates diagrams for the Confusion matrix, Precision, recall and F1 score, Receiver operator characteristics (ROC) and area under ROC (AUC) as follows:
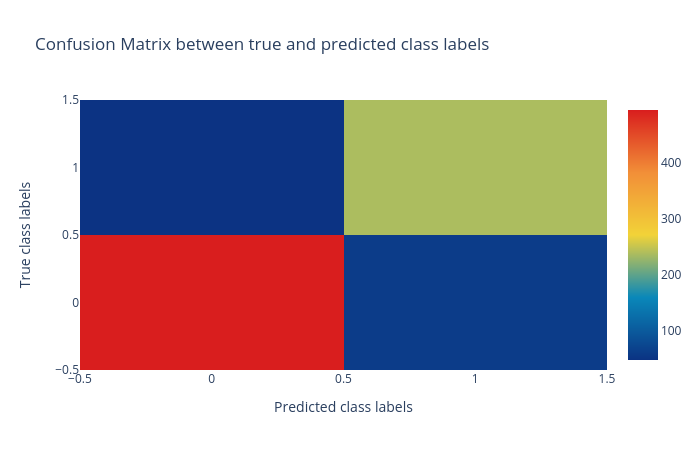
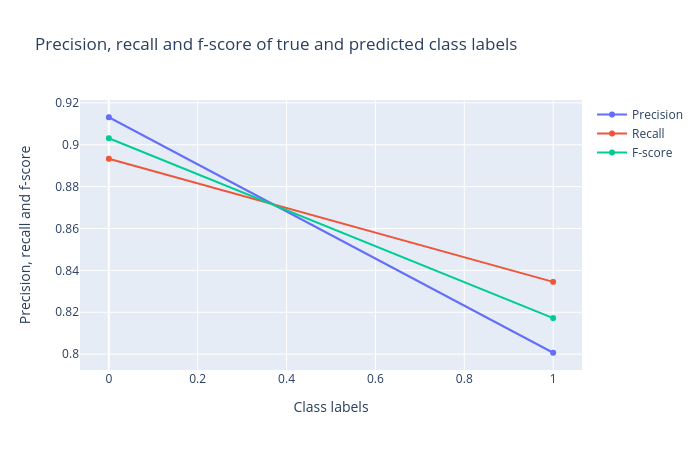
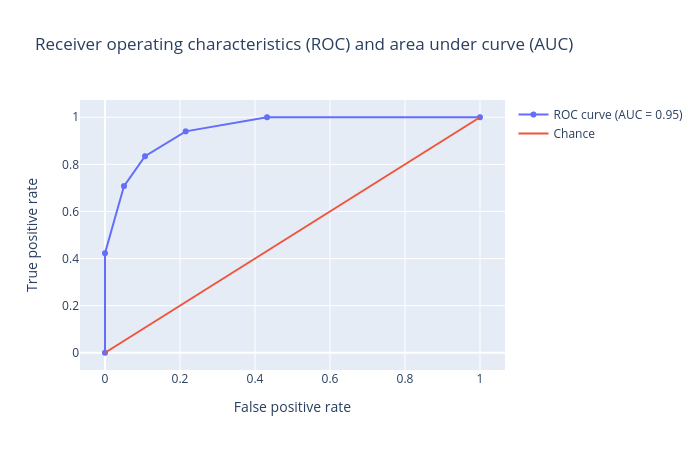
Support Vector Machines (SVM)
Support Vector Machines (SVMs) have been extensively researched in the machine learning community for the last decade and actively applied to applications in various domains such as bioinformatics. SVM is a generalization of a classifier called maximal margin classifier and is introduced as a binary classifier intended to separate two classes when obtaining the optimal hyperplane and decision boundary. SVMs are based on the assumption that the input data can be linearly separable in a geometric space. The maximal margin classifier is simple, but it cannot be applied to the majority of datasets, since the classes must be separated by a linear boundary and this is often not the case when working with real world data. That is why the support vector classifier was introduced as an extension of the maximal margin classifier, which can be applied in a broader range of cases.
To solve this problem, SVM uses kernel functions to map the input to a high dimension feature space, i.e hyperplane, where a linear decision boundary is constructed in such a manner that the boundary maximises the margin between two classes. The kernel approach is simply an efficient computational approach for accommodating a non-linear boundary between classes.
Without going into technical details, a kernel is a function that quantifies the similarity of two observations. Two special properties of SVMs are that SVMs achieve (1) high generalization by maximizing the margin and (2) support an efficient learning of nonlinear functions by kernel trick. In the next step, we will build a SVM classifier with our data.
Hands-on: Train a SVM classifier
- Support vector machines (SVMs) tool with the following parameters to train the regressor:
- “Select a Classification Task”:
Train a model
- “Select a linear method”:
Linear Support Vector Classification
- “Select input type”:
tabular data
- param-file “Training samples dataset”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
All columns EXCLUDING some by column header name(s)
- param-text “Type header name(s)”:
Class- param-file “Dataset containing class labels”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
Select columns by column header name(s)
- param-text “Select target column(s)”:
Class- Rename the generated file to
SVM_model
QuestionWhat is learned by the support vector machines?
The coefficients of the line with the maximal margin in the kernel space is learned in the training phase.
Now we will evaluate the performance of the SVM classifier:
Hands-on: Predict class SVM classifier
- Support vector machines (SVMs) tool with the following parameters to predict targets of test dataset using the trained model:
- “Select a Classification Task”:
Load a model and predict
- param-file “Models”:
SVM_model- param-file “Data (tabular)”:
test_rows- param-check “Does the dataset contain header”:
Yes- param-select “Select the type of prediction”:
Predict class labels- Rename the generated file to
SVM_result
Now let’s visualize the results:
Hands-on: Check and visualize the classification
- Plot confusion matrix, precision, recall and ROC and AUC curves tool with the following parameters to visualize the classification:
- param-file “Select input data file”:
test_rows_labels- param-file “Select predicted data file”:
SVM_result- param-file “Select trained model”:
SVM_model
The visualization tool creates the following ROC plot:
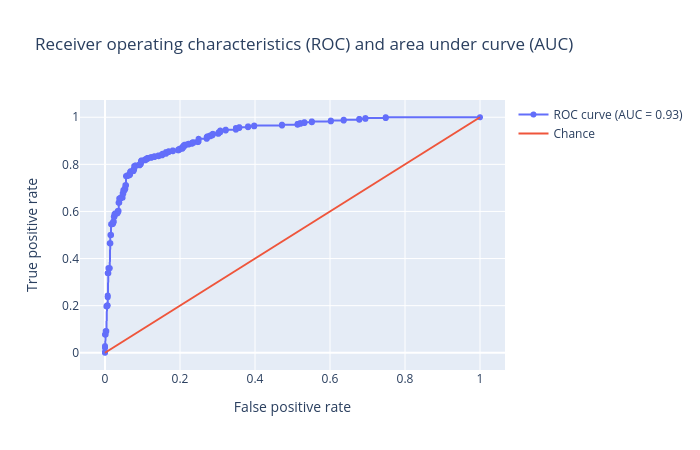
Random Forest
Random forest is an ensemble of decision trees, and usually trained with the “bagging” method. The Ensemble method uses multiple learning models internally for better predictions and the general idea of the bagging method is that a combination of learning models increases the overall result. It uses multiple decision tree regressors internally and predicts by taking the collective performances of the predictions by multiple decision trees. It has a good predictive power and is robust to outliers. It creates an ensemble of weak learners (decision trees) and iteratively minimizes error.
One big advantage of random forest is that it can be used for both classification and regression problems. The main idea behind the random forest is adding additional randomness to the model, while growing the trees and instead of searching for the most important feature while splitting a node, it searches for the best feature among a random subset of features. This results in a better model because of wide diversity. Generally, the more trees in the forest, the more robust the model. Therefore, when using the random forest classifier, a larger number of trees in the forest gives higher accuracy results. Similarly there are two stages in the random forest algorithm: one is random forest creation, the other is to make a prediction from the random forest classifier created in the first stage.
Hands-on: Train random forest
- Ensemble methods tool with the following parameters to train the regressor:
- “Select a Classification Task”:
Train a model
- “Select an ensemble method”:
Random forest classifier
- “Select input type”:
tabular data
- param-file “Training samples dataset”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
All columns EXCLUDING some by column header name(s)
- param-text “Type header name(s)”:
Class- param-file “Dataset containing class labels”:
train_rows- param-check “Does the dataset contain header”:
Yes- param-select “Choose how to select data by column”:
Select columns by column header name(s)
- param-text “Select target column(s)”:
Class- Rename the generated file to
RandomForest_model
QuestionWhat are the advantages of random forest classifier compared with KNN and SVM?
- The overfitting problem will never arise when we use the random forest algorithm in any classification problem.
- The same random forest algorithm can be used for both classification and regression task.
- The random forest algorithm can be used for feature engineering, which means identifying the most important features out of the available features from the training dataset.
After learning on the training dataset, we should evaluate the performance on the test dataset.
Hands-on: Predict targets using the random forest
- Ensemble methods tool with the following parameters to predict targets of test dataset using the trained model:
- “Select a Classification Task”:
Load a model and predict
- param-file “Models”:
RandomForest_model- param-file “Data (tabular)”:
test_rows- param-check “Does the dataset contain header”:
Yes- param-select “Select the type of prediction”:
Predict class labels- Rename the generated file to
RandomForest_result
The visualization tool creates the following ROC plot:
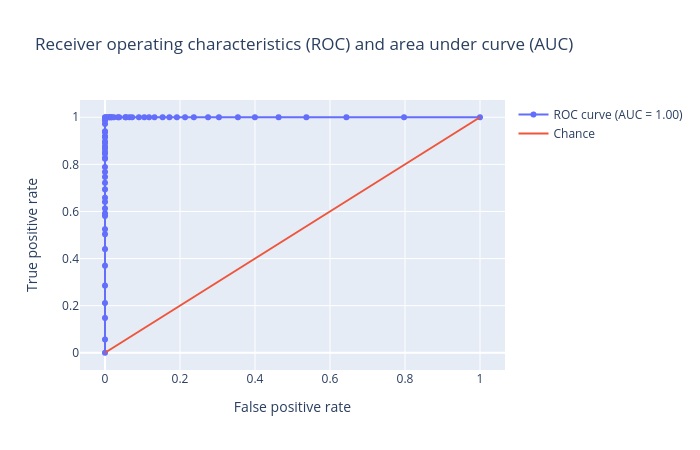
QuestionInspect the plots. What can you say about the classification?
Figures show that we achieved an AUC score of
1.0for the test set using random forest. It means the prediction is very good, in fact it has no error at all. Unfortunately, this is not usually the case when dealing with chemical data.
Create data processing pipeline
At the last step, we will create a bagging classifier by using the Pipeline builder tool. Bagging or Bootstrap Aggregating is a widely used ensemble learning algorithm in machine learning. The bagging algorithm creates multiple models from randomly taken subsets of the training dataset and then aggregates learners to build overall stronger classifiers that combine the predictions to produce a final prediction. The Pipeline builder tool builds the classifier and returns a zipped file. This tool creates another file which is tabular and contains a list of all the different hyperparameters of the preprocessors and estimators. This tabular file will be used in the Hyperparameter search tool to populate the list of hyperparameters with their respective (default) values.
Hands-on: Create pipeline
- Pipeline builder tool with the following parameters:
- In “Final Estimator”:
- “Choose the module that contains target estimator”:
sklearn.ensemble
- “Choose estimator class”:
BaggingClassifierIn “Output parameters for searchCV?”:
YesWe choose
Final Estimatoras we have only the estimator and no preprocessor and need the parameters of only the estimator.
Search for the best values of hyperparameters
After extracting the parameter names from the Pipeline builder file, we will use the Hyperparameter search tool to find the best values for each hyperparameter. These values will lead us to create the best model based on the search space chosen for each hyperparameter. We use only one parameter n_estimators of BaggingClassifier for this task. This parameter specifies the number of bagging stages the learning process has to go through. The default value of n_estimators for this regressor is 10. However, we are not sure if this gives the best accuracy. Therefore, it is important to set this parameter to different values to find the optimal one. We choose a value which is less than 10 and a few which are more than 10. The hyperparameter search will look for the optimal number of estimators and gives the best-trained model as one of the outputs. This model is used in the next step to classify the test dataset.
Hands-on: Hyperparameter search
- Hyperparameter search tool with the following parameters:
- “Select a model selection search scheme”:
GridSearchCV - Exhaustive search over specified parameter values for an estimator
- param-files “Choose the dataset containing pipeline/estimator object”:
zippedfile (output of Pipeline builder tool)- param-files “Is the estimator a deep learning model?”:
NOtool)- In “Search parameters Builder”:
- param-files “Choose the dataset containing parameter names”:
tabularfile (output of Estimator attributes tool)- In “Parameter settings for search”:
- param-repeat “1: Parameter settings for search”
- “Choose a parameter name (with current value)”:
n_estimators: 10- “Search list”:
[5,10,20,50]- “Select input type”:
tabular data
- param-files “Training samples dataset”:
train_rowstabular file- “Does the dataset contain header”:
Yes- “Choose how to select data by column”:
All columns BUT by column header name(s)
- “Type header name(s)”:
Class- param-files “Dataset containing class labels or target values”:
train_rowstabular file- “Does the dataset contain header”:
Yes- “Choose how to select data by column”:
Select columns by column header name(s)
- “Type header name(s)”:
Class- “Whether to hold a portion of samples for test exclusively?”:
Nope- “Save best estimator?”:
Fitted best estimator or Detailed cv_results_from nested CV
QuestionWhat is the optimal number of estimators for the given dataset?
Hint: Please look at the
mean_test_scorecolumn in the tabular result from the Hyperparameter search tool.20 - even though the default value of the number of estimators for Bagging Classifier is
10,20gives the best accuracy. That’s why it is important to perform hyperparameter search to tune these parameters for any dataset.
Using the Hyperparameter search tool, we found the best model, based on the training data. Now, we will predict age in the test dataset using this model.
Hands-on: Predict age
- Ensemble methods for classification and regression tool with the following parameters:
- “Select a Classification Task”:
Load a model and predict
- param-files “Models”:
zippedfile (output of Hyperparameter search tool)- param-files “Data (tabular)”:
test_rowstabular file- “Does the dataset contain header”:
Yes
Now we will verify the performance by creating and inspecting the plots:
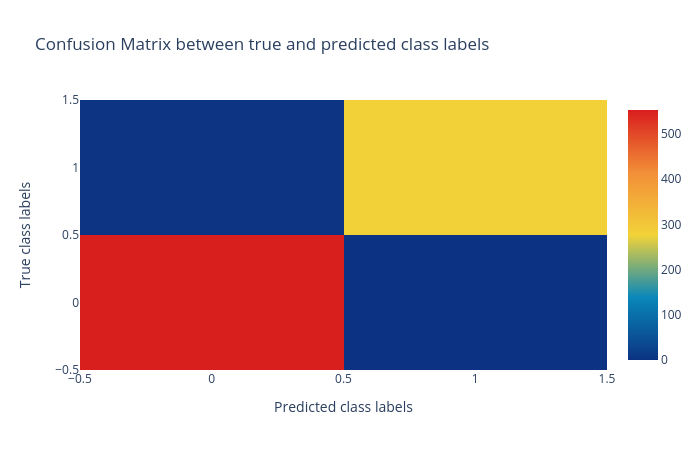
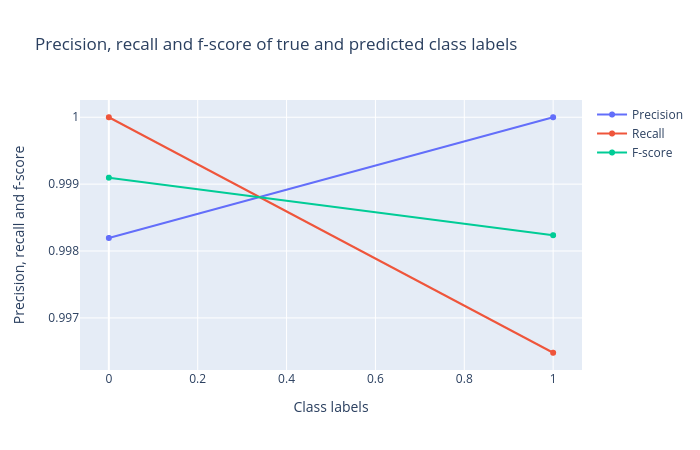
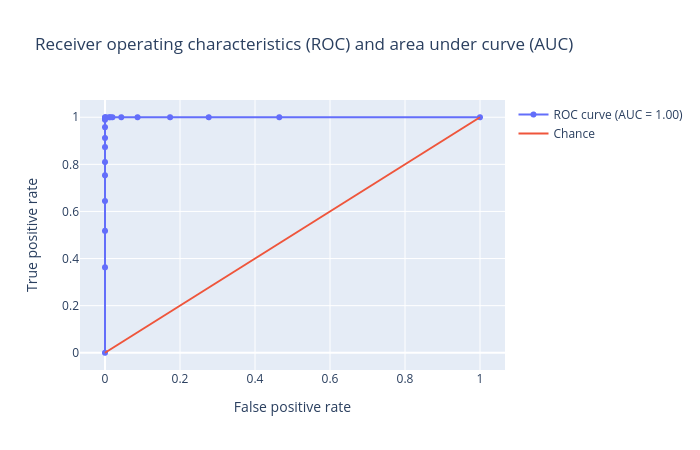
Figure 13 shows that we again achieved an AUC value of 1.00, which shows that our model is highly effective at predicting whether or not a molecule is biodegradable.
Conclusion
By following these steps, we learned how to build classifiers and visualize the classification results using Galaxy’s machine learning and plotting tools. The features of the training dataset are mapped to the classes. This mapping is used to make predictions on an unseen (test) dataset. The quality of classifiers is visualized using a plotting tool.
There are multiple other classification algorithms, a few are simpler to use (with fewer parameters) and some are more powerful, which can be tried out on this dataset and on other datasets as well. Different datasets can also be analyzed using these classifiers. The classifiers have many parameters which can be altered while performing the analyses to see if they affect the classification accuracy. It may be beneficial to perform a hyperparameter search to tune these parameters for different datasets. In addition, we learned the relevance of machine algorithms for QSAR analyses and constructed a model which successfully predicted an important chemical property - the biodegradability of a substance.
Key points
Classification is a supervised approach in machine learning.
For classification tasks, data is divided into training and test sets.
Using classification, the samples are learned using the training set and predicted using the test set.
For each classification algorithm, it parameters should be optimised based on the dataset.
Machine learning algorithms can be applied to chemical datasets to predict important properties.
Frequently Asked Questions
Have questions about this tutorial? Check out the tutorial FAQ page or the FAQ page for the Statistics and machine learning topic to see if your question is listed there. If not, please ask your question on the GTN Gitter Channel or the Galaxy Help ForumFeedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Alireza Khanteymoori, Anup Kumar, Simon Bray, 2022 Classification in Machine Learning (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/statistics/tutorials/classification_machinelearning/tutorial.html Online; accessed TODAY
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{statistics-classification_machinelearning, author = "Alireza Khanteymoori and Anup Kumar and Simon Bray", title = "Classification in Machine Learning (Galaxy Training Materials)", year = "2022", month = "10", day = "18" url = "\url{https://training.galaxyproject.org/training-material/topics/statistics/tutorials/classification_machinelearning/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Batut_2018, doi = {10.1016/j.cels.2018.05.012}, url = {https://doi.org/10.1016%2Fj.cels.2018.05.012}, year = 2018, month = {jun}, publisher = {Elsevier {BV}}, volume = {6}, number = {6}, pages = {752--758.e1}, author = {B{\'{e}}r{\'{e}}nice Batut and Saskia Hiltemann and Andrea Bagnacani and Dannon Baker and Vivek Bhardwaj and Clemens Blank and Anthony Bretaudeau and Loraine Brillet-Gu{\'{e}}guen and Martin {\v{C}}ech and John Chilton and Dave Clements and Olivia Doppelt-Azeroual and Anika Erxleben and Mallory Ann Freeberg and Simon Gladman and Youri Hoogstrate and Hans-Rudolf Hotz and Torsten Houwaart and Pratik Jagtap and Delphine Larivi{\`{e}}re and Gildas Le Corguill{\'{e}} and Thomas Manke and Fabien Mareuil and Fidel Ram{\'{\i}}rez and Devon Ryan and Florian Christoph Sigloch and Nicola Soranzo and Joachim Wolff and Pavankumar Videm and Markus Wolfien and Aisanjiang Wubuli and Dilmurat Yusuf and James Taylor and Rolf Backofen and Anton Nekrutenko and Björn Grüning}, title = {Community-Driven Data Analysis Training for Biology}, journal = {Cell Systems} }