Empathy
Contributors

 Helena Rasche
Helena Rasche
 Saskia Hiltemann
Saskia Hiltemann
Part of the Job
We are not just janitors / code monkeys
- We’re humans with feelings
- Our users are humans with feelings as well
- Both groups need to be understanding of each other
We’re (often) the point of contact for any problems
- It’s our responsibility to fix Galaxy problems
- Or any server problems for our users
- Or sometimes anything that is electrical is our problem
Speaker Notes
We need to talk and not just talk but communicate with each other, listen to each other’s complaints and problems. You can only control 1/2 of the equation, but you can have a positive impact on the balance.
You’re also often the Tier 1 response to issues, so even when you’re stressed, users often just want to feel heard, like they’ve told someone and their complaint has been heard. Doing this can help defuse bad situations where people are upset and feelings are hurt.
SLAs vs SLOs
- Academic services rarely have SLAs
- But defining your own SLO can be good! Freedom to say “it’s ok, it will be down for some time”
EU SLOs (not SLAs)*
| Service | SLO | Permitted Outage (30d) | Critical | User-Facing? |
|---|---|---|---|---|
| Haproxy | 99.9% | 43 minutes | Yes | Yes |
| Cluster | 95.0% | 36 hours | Yes | No |
| Sentry | 50.0% | 15 day | No | No |
| Jenkins | 50.0% | 15 day | No | Yes-ish |
| Grafana | 50.0% | 15 day | No | Yes-ish |
.footnote[
* SLA = Service Level Agreement, SLO = Service Level Objective
]
Speaker Notes
- SLA = Service Level Agreement, Legal agreement with your users, usually with financial penalties for failing to reach the level.
- SLO = Service Level Objective, your goal for your service, showing your users you’re committed to trying to reach that number.
Service Level Objectives are just your goals, not a legal agreement with your users. It’s just a number that you plan to hit, that you can share with your users to give them an idea of your goals.
Bad things happen
- It’s unavoidable with so many interconnected devices:
- Network
- DC
- Server
- Service
- Be kind to your fellow admins/network engineers/support people, maybe it’s their turn to have a bad day
- Spend time engineering to avoid problems
- But consider the system’s SLA/SLO
Speaker Notes
Reliability engineering is difficult
Communication
Communication Communication Communication
- Users often just want to know when the service will be back, or that their jobs are still running
- So write helpful notifications before, during, after planned outages
- Write posts after unplanned outages
- Add graphics
- Try and be empathetic in your communications
- Give users the benefit of the doubt
- Acknowledge their feelings but try not to take it as a personal attack (even when it is.)
- Emails:
- When receiving (uncharacteristically) unpleasant ones, imagine a loved one wrote it? Wouldn’t you give them a break?
- When writing, imagine your loved one is receiving it. How would they feel?
Speaker Notes
Common advice: respond calmly, do not send emails immediately, come back to it in a few hours
Shared Responsibility
Documentation Documentation Documentation
- Document your code/infrastructure/everything
- You will probably change jobs, and someone else will have to maintain your code
- Someone else will debug your code at 3 AM and hate you
- You’ve probably had to do the same with someone else’s code
- Write code to be read by humans first, and machines second
Speaker Notes
Have you ever had to debug something that was broken, late at night? And it was broken and someone else’s fault and it didn’t behave how it was documented? And you were up late swearing up and down at this other person for their bad code that’s causing you to lose sleep?
We all do it to each other, we just have to try to be better. It’s an uphill battle, and it’s difficult every day to write that documentation and force yourself into these good habits.
Small Changes, Big Impacts
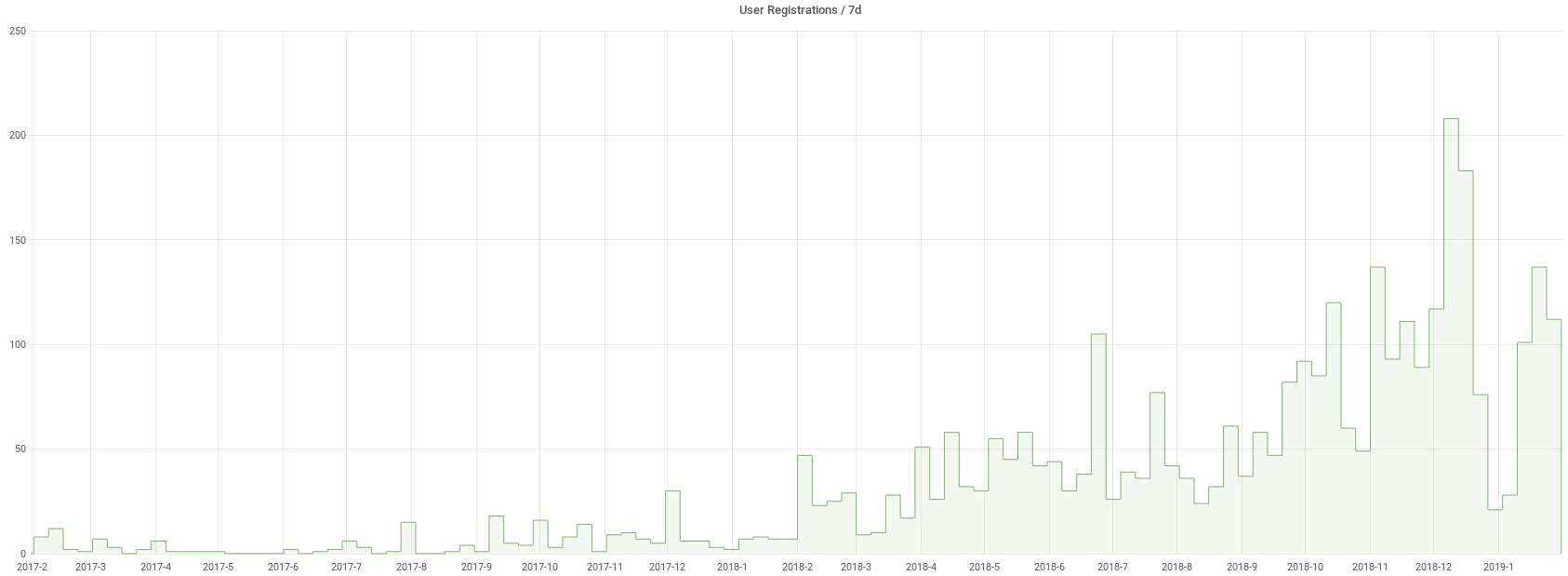
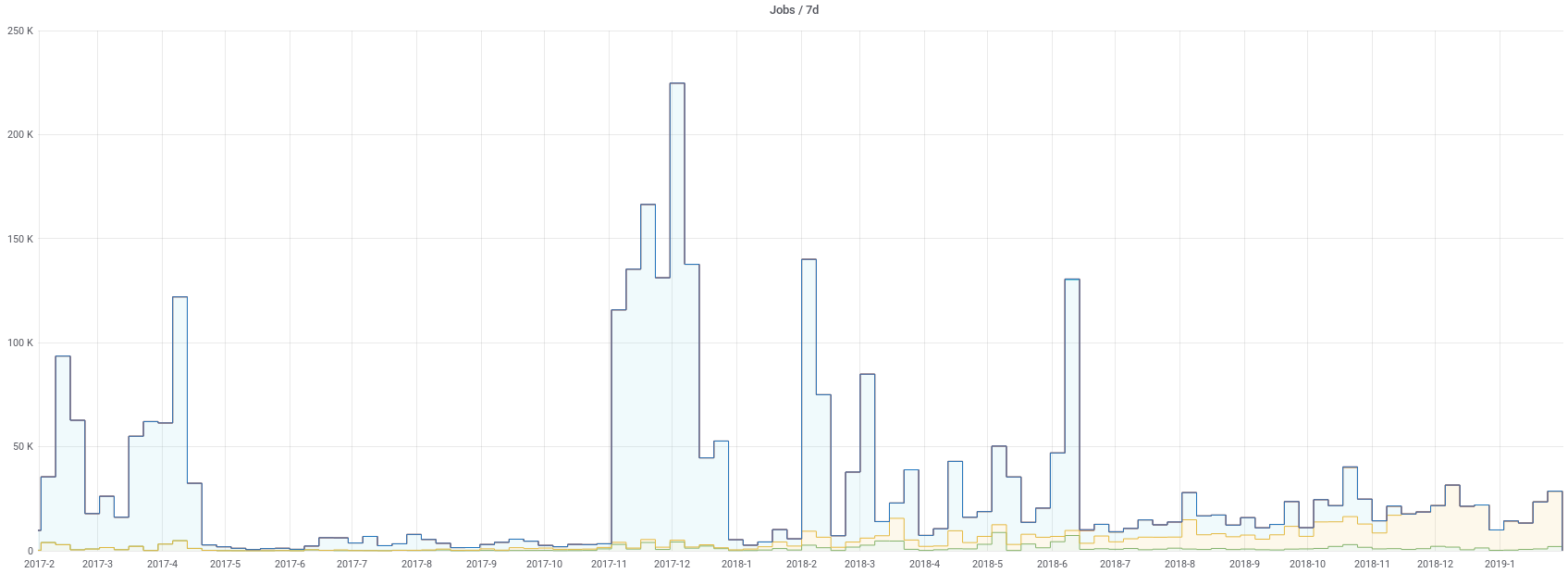
Be careful with what changes you make in production; all of your users are depending on you to do their work
Speaker Notes
Any change you make to a production system is multiplied by the number of active users. As of this writing EU has ~800 monthly active users. Even small changes affect everyone so be careful and have a dev environment to deploy to first.
As an example, we had a partially working system, it was working for 95% of our users on friday night. One of our admins made a change in production to try and fix the 5%, but instead it took the system down for everyone. This is the sort of example of “be really careful” that is illuminating, not only was the service now offline for everyone (unlike the 95% functional case where we could have left it until monday morning), but the admin had to spend another hour reverting the changes.
Self Care
Take care of yourself! Being a sysadmin is a difficult and thankless job, do not do it at the expense of your mental or physical health:
| Area | Suggestions |
|---|---|
| Mental Health | Take breaks, walk around, clear your head. Do not skip lunch with coworkers, join them. |
| External Environment | See sunlight regularly, living in caves is bad for you |
| Office Environment | Request a standing desk, or using an exercise ball in lieu of a seat |
| Stress | You (probably) work in an academic environment, if the service is down, it’s down. You have SLOs and not SLAs, and if you miss them one month it is ok. Respect your work-life balance. |
Speaker Notes
Your health is more important than the health of the servers.
Take Home
Explicit Goals:
–
- You’re happy
- Your users are happy
–
It is not a zero-sum game, both of these can be true (or true enough), and both of these are worth working towards.
Recommendations
- Communicate clearly and empathetically
- You’re the single point of failure, engineer away from this
- Document what you do for yourself and the next person
Thank you!
This material is the result of a collaborative work. Thanks to the Galaxy Training Network and all the contributors! This material is licensed under the Creative Commons Attribution 4.0 International License.
This material is licensed under the Creative Commons Attribution 4.0 International License.