name: inverse layout: true class: center, middle, inverse <div class="my-header"><span> <a href="/training-material/topics/assembly" title="Return to topic page" ><i class="fa fa-level-up" aria-hidden="true"></i></a> <a class="nav-link" href="https://github.com/galaxyproject/training-material/edit/main/topics/assembly/tutorials/assembly-quality-control/slides.html"><i class="fa fa-pencil" aria-hidden="true"></i></a> </span></div> <div class="my-footer"><span> <img src="/training-material/assets/images/GTN-60px.png" alt="Galaxy Training Network" style="height: 40px;"/> </span></div> --- <img src="/training-material/assets/images/GTN.png" alt="Galaxy Training Network" class="cover-logo"/> # Genome assembly quality control. <div markdown="0"> <div class="contributors-line"> Authors: <a href="/training-material/hall-of-fame/abretaud/" class="contributor-badge contributor-abretaud"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/abretaud?s=27" alt="Avatar">Anthony Bretaudeau</a> <a href="/training-material/hall-of-fame/alexcorm/" class="contributor-badge contributor-alexcorm"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/alexcorm?s=27" alt="Avatar">Alexandre Cormier</a> <a href="/training-material/hall-of-fame/stephanierobin/" class="contributor-badge contributor-stephanierobin"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/stephanierobin?s=27" alt="Avatar">Stéphanie Robin</a> <a href="/training-material/hall-of-fame/r1corre/" class="contributor-badge contributor-r1corre"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/r1corre?s=27" alt="Avatar">Erwan Corre</a> <a href="/training-material/hall-of-fame/lleroi/" class="contributor-badge contributor-lleroi"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/lleroi?s=27" alt="Avatar">Laura Leroi</a> <a href="/training-material/hall-of-fame/chklopp/" class="contributor-badge contributor-chklopp"><img src="https://avatars.githubusercontent.com/chklopp?s=27" alt="Avatar">Christophe Klopp</a> </div> </div> <!-- modified date --> <div class="footnote" style="bottom: 8em;"><i class="far fa-calendar" aria-hidden="true"></i><span class="visually-hidden">last_modification</span> Updated: Sep 20, 2022</div> <!-- other slide formats (video and plain-text) --> <div class="footnote" style="bottom: 6em;"> <i class="fas fa-file-alt" aria-hidden="true"></i><span class="visually-hidden">text-document</span><a href="slides-plain.html"> Plain-text slides</a> </div> <!-- usage tips --> <div class="footnote" style="bottom: 2em;"> <strong>Tip: </strong>press <kbd>P</kbd> to view the presenter notes | <i class="fa fa-arrows" aria-hidden="true"></i><span class="visually-hidden">arrow-keys</span> Use arrow keys to move between slides </div> ??? Presenter notes contain extra information which might be useful if you intend to use these slides for teaching. Press `P` again to switch presenter notes off Press `C` to create a new window where the same presentation will be displayed. This window is linked to the main window. Changing slides on one will cause the slide to change on the other. Useful when presenting. --- ## Requirements Before diving into this slide deck, we recommend you to have a look at: - [Introduction to Galaxy Analyses](/training-material/topics/introduction) - [Sequence analysis](/training-material/topics/sequence-analysis) - Quality Control: [<i class="fab fa-slideshare" aria-hidden="true"></i><span class="visually-hidden">slides</span> slides](/training-material/topics/sequence-analysis/tutorials/quality-control/slides.html) - [<i class="fas fa-laptop" aria-hidden="true"></i><span class="visually-hidden">tutorial</span> hands-on](/training-material/topics/sequence-analysis/tutorials/quality-control/tutorial.html) --- ### <i class="far fa-question-circle" aria-hidden="true"></i><span class="visually-hidden">question</span> Questions - Assembly: Is my genome assembly ready for scaffolding? - Annotation: Is my genome assembly ready for structural annotation? --- # Genome assembly quality control, or "the 3C" <br> <br> .image-100[ 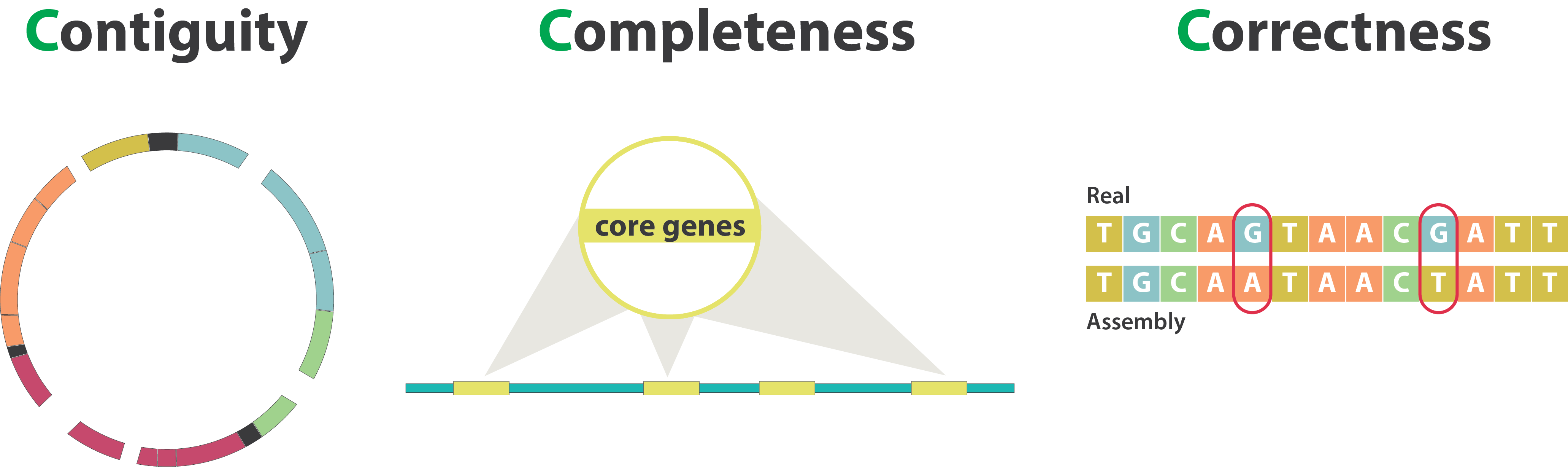 ] --- .image-30[ 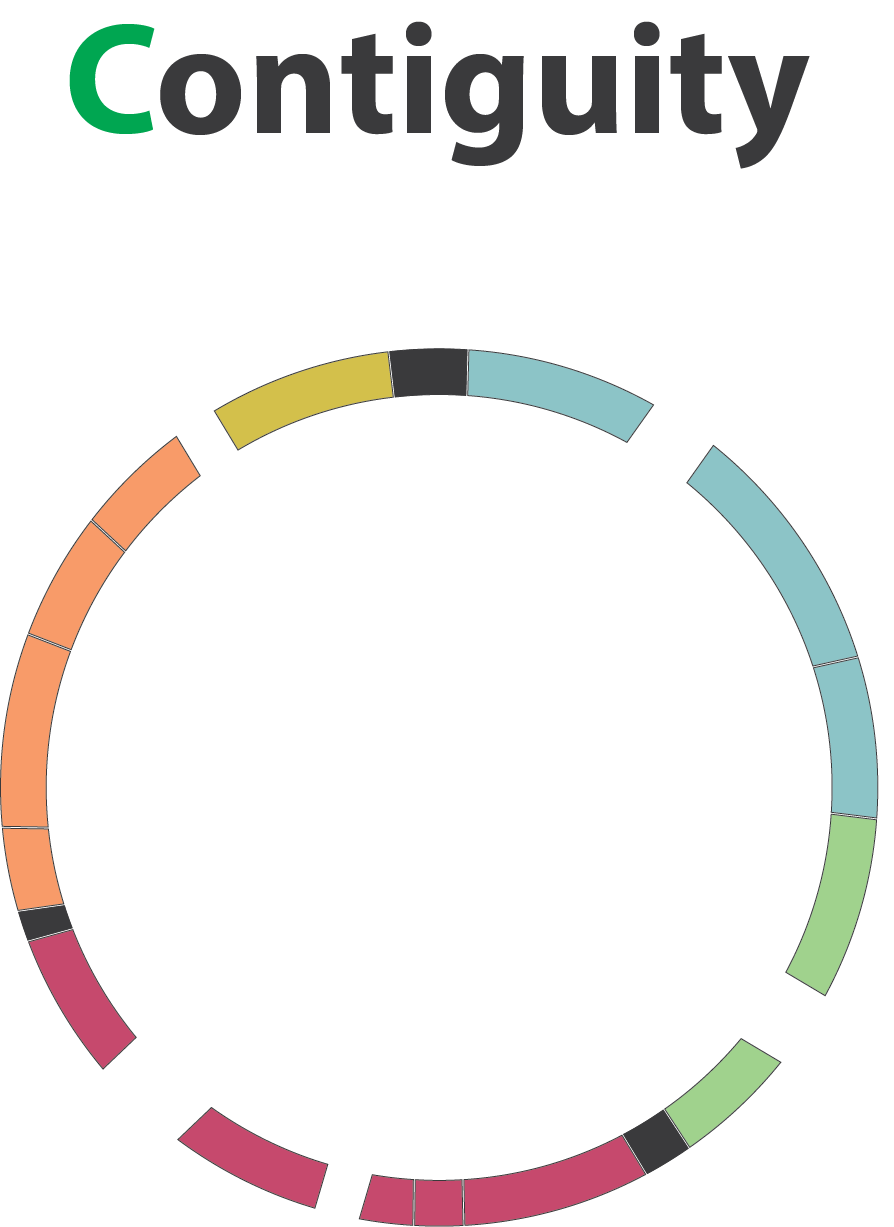 ] --- ### **C**ontiguity .pull-left[ **Desire** - Fewer sequences - Longer sequences ] .pull-right[ **Metrics**: - Number of sequences - Average sequences length - Median sequences length - Minimum and maximum sequences length - N50, NG50, L50, LG50 - GC content - Number and proportion of bases that are N ] **Sequences**, i.e. a set of contigs and/or scaffolds --- ### N50 & L50 .left[ **N50**: given a set of sequences of varying lengths, the N50 is defined as **the length L of the shortest contig** for which **longer and equal length contigs cover at least 50% of the assembly**. **L50**: given a set of sequences of varying lengths, the L50 is defined as **count of smallest number of sequences** whose **length sum makes up 50% of the assembly**. ] **N50 describes a sequence length whereas L50 describes a number of sequences.** --- ### N50 & L50 .pull-left[ Example: - Genome size = 100 - Sequence sorted by size list L = (25, 10, 10, 8 , 7, 7 , 6 , 5, 5, 5, 5, 3, 2, 2 ) = 100 - 50% of the total length is contained within sequences of at least 8bp: 25 + 10 + 10 + 8 ≥ 50 ] .image-100[  ] **N50 = 8** and **L50 = 4** .footnote[Alhakami, H., Mirebrahim, H., & Lonardi, S. (2017). A comparative evaluation of genome assembly reconciliation tools. Genome biology, 18(1), 1-14.] --- ### N50 & L50 However, the theses statistics may not reflect some assembly improvements. If we connect two sequences longer than N50 or connect two sequences shorter than N50, N50 is not changed. N50 is only improved if we connect a sequence shorter than N50 and a sequence longer than N50. .image-40[  ] --- ### Nx curve « 50 » is a single point on the Nx curve. The entire Nx curve in fact gives us a better sense of contiguity. .pull-left[ 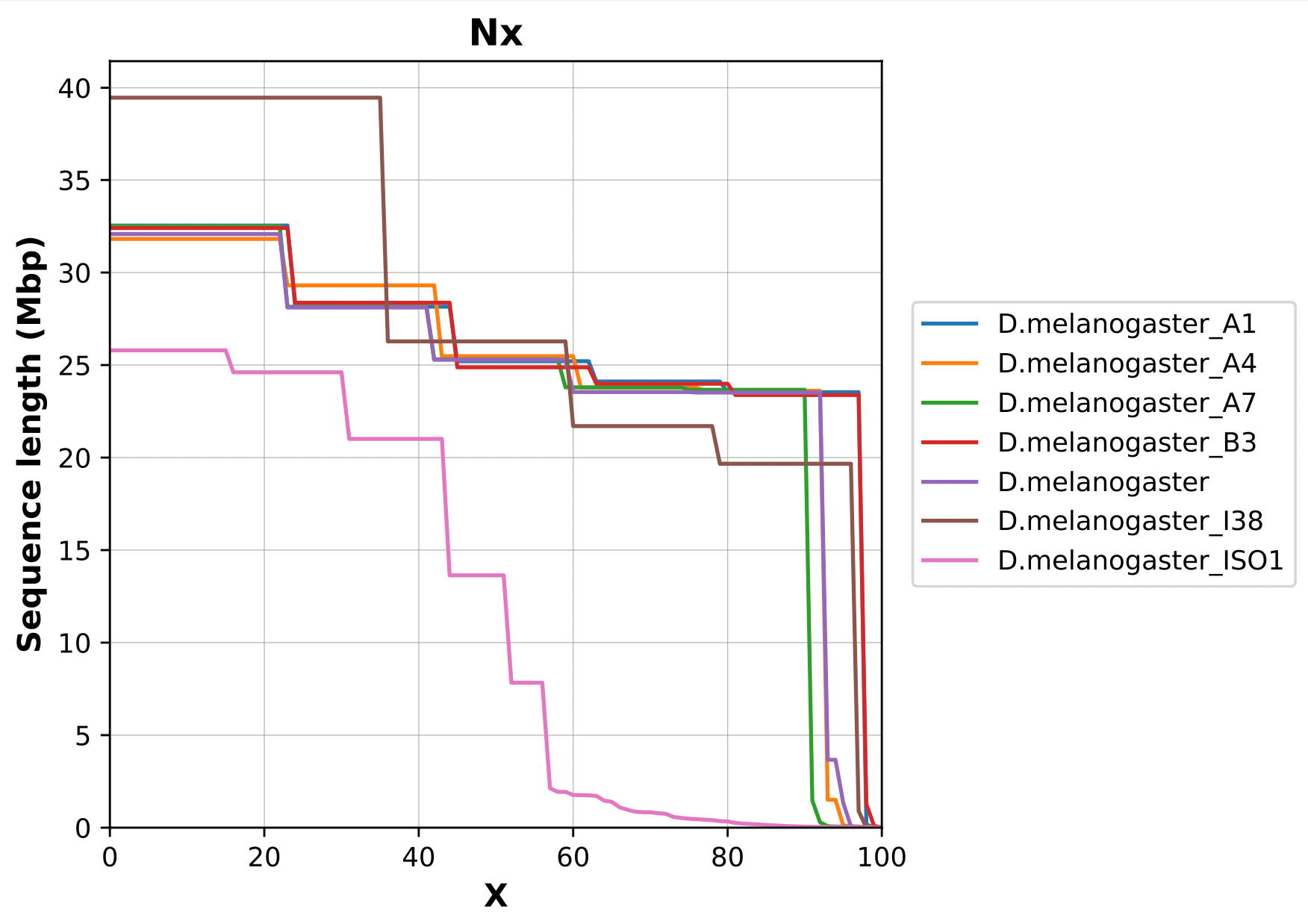 ] .pull-right[ 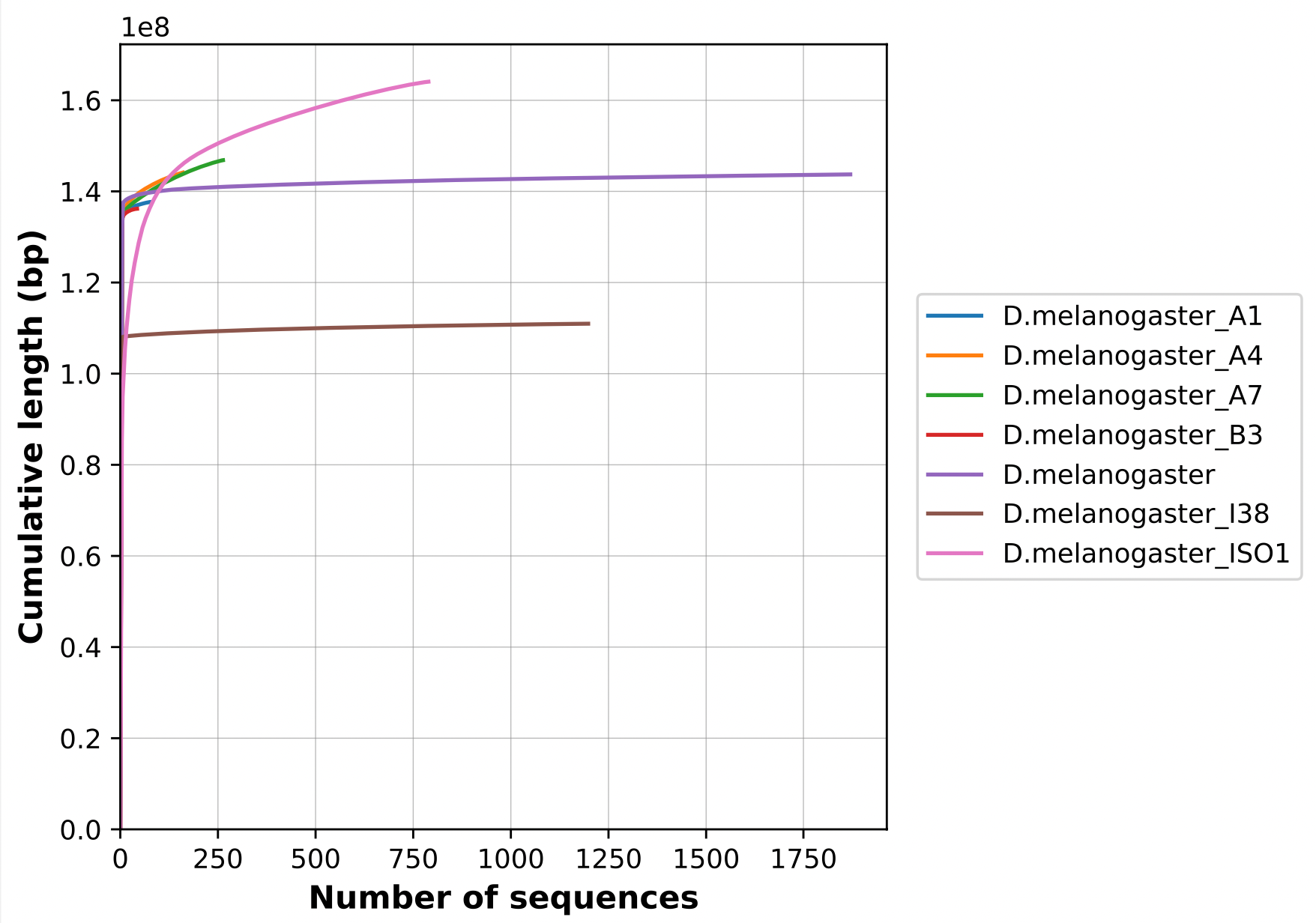 ] --- ### QUAST - A tool to evaluate genome assemblies - **QUAST**: for genome assemblies. - **MetaQUAST**: for metagenomic datasets. - **QUAST-LG**: for large genomes (e.g., mammalians). - **rnaQUAST**: for RNAseq. - **Icarus**: an interactive visualizer for these tools. It also includes: - Reads mapping (mi-assemblies evaluation). - Kmer representation (KMC) - Structural prediction modules (GeneMark, GlimmerHMM, Barrnap and BUSCO). - For metagenomics dataset: MetaGeneMark, Krona tools, BLAST, and SILVA 16S rRNA database. --- .image-30[  ] --- ### Types of completeness - Assembly size - Known vs. unknown nucleotides - "Core" genes - Assembly kmer content - Reads mapping and assembly coverage --- ### Assembly size vs estimated Proportion of the original genome represented by the assembly: .image-100[  ] "*" it’s an estimation, so not perfect. See  to find methods to determine the genome size. --- ### Known vs. unknown nucleotides Proportion of A, T, G, C versus N (unknown nucleotide).We expect an assembly without unknown nucleotides (N). --- ### "Core" genes .pull-left[ Quantitative assessment of genome assembly based on evolutionarily informed expectations of gene content from near-universal single-copy orthologs. .image-70[  ] ] .pull-right[ .image-70[  ]] .footnote[Tips: Reference databases are constructed using known genomes. Species with few/no close genomes available can have very bad scores.] --- ### Core genes evaluation software **BUSCO**: Assessing genome assembly and annotation completeness with **B**enchmarking **U**niversal **S**ingle-**C**opy **O**rthologs .pull-left[ .image-70[  ]] .pull-right[ .image-60[  ]] Eukaryota: 255 single copy from 70 species; Arthropoda: 1013 single copy from 90 species; Fungi: 758 single copy from 549 species .footnote[Waterhouse, R. M., Zdobnov, E. M. & Kriventseva, E. V. Correlating Traits of Gene Retention, Sequence Divergence, Duplicability and Essentiality in Vertebrates, Arthropods, and Fungi. Genome Biol Evol 3, 75–86 (2011).] --- ### BUSCO limitations **The value of the BUSCO is only as good as its reference database.** <br> Example with BUSCO Eukaryotic set: .pull-left[ .image-70[  ]] .pull-right[ .image-70[  ]] .footnote[Saary, P., Mitchell, A. L. & Finn, R. D. Estimating the quality of eukaryotic genomes recovered from metagenomic analysis with EukCC. Genome Biol 21, 244 (2020).] --- ### BUSCO limitations The use of transcriptome alignment of a closely related species or a de novo RNA-Seq assembly of the same species can be another proxy to assess the completeness of the assembly and adress BUSCO limitations. --- ### Assembly kmer content The aim is to check assembly coherence against the content within reads that were used to produce the assembly. Basically, how many elements of each frequency on the read’s spectrum ended up being not included in the assembly, included once, included twice etc. <br> <br> - Merqury or KAT - Histogram is build with read kmer content. --- ### K-mer spectrum plots .pull-left[ .image-70[  ]] .pull-right[ .image-70[  ]] .footnote[Rhie, A., Walenz, B. P., Koren, S. & Phillippy, A. M. Merqury: reference-free quality, completeness, and phasing assessment for genome assemblies. Genome Biol 21, 245 (2020).] --- ### Assembly kmer content - Homozygous genomes .image-70[  ] <i class="far fa-thumbs-up" aria-hidden="true"></i><span class="visually-hidden">congratulations</span> Good kmer representation of reads in the assembly --- ### Assembly kmer content - Homozygous genomes .image-70[  ] <i class="fa fa-thumbs-down"></i> Bad kmer representation of reads in the assembly --- ### Assembly kmer content - Heterozygous genomes <br> .image-70[  ] <i class="far fa-thumbs-up" aria-hidden="true"></i><span class="visually-hidden">congratulations</span> Good kmer representation of reads in the assembly The lost content (the black peak) represents the half of the heterozygous content that is lost when bubbles are collapsed. --- ### Assembly kmer content - Heterozygous genomes .image-80[  ] <i class="fa fa-thumbs-down"></i> Bad kmer representation of reads in the assembly --- ### Reads mapping and assembly coverage <br> - **Proportion of mapped vs. unmapped reads** i.e. proportion of missing parts in the assembly - **Coverage in terms of redundancy (A)**: number of reads that align to, or "cover," a known reference. - **Coverage in terms of the percentage coverage of a reference by reads (B)**: E.g. if 90% of a reference is covered by reads (and 10% not) it is a 90% coverage. .image-60[  ] --- .image-30[  ] --- ### Mistakes into the assembly ** Proportion of the assembly that is free from mistakes** <br> <br> - Indels / SNPs - Mis-joins - Repeat compressions - Unnecessary duplications - Rearrangements <br> <br> **→ Align back reads to the assembly and check for inconsistencies** --- ### SNP / indels errors .image-80[  ] --- ### Other mis-assemblies .image-80[  ] --- ### Other mis-assemblies .image-80[  ] --- ### Switch and hamming errors (phased assemblies) .pull-left[ .image-70[  ] In red, heterozygous locus from second haplotype. In blue, heterozygous locus from first haplotype. ] .pull-right[ - **Switch error**: a change from one parental allele to another parental allele on a contig. This terminology has been used for measuring reference-based phasing accuracy for two decades. A haplotig is supposed to have no switch errors. - **Yak hamming error**: an allele not on the most supported haplotype of a contig. Its main purpose is to test how close a contig is to a haplotig. The yak definition is not widely accepted. The hamming error rate is arguably less important in practice. ] .footnote[http://lh3.github.io/2021/04/17/concepts-in-phased-assemblies] --- # Evaluation against reference genome .image-30[  ] --- .pull-left[ .left[ Dot plots are widely used to quickly compare 2 sequence sets. They provide a synthetic overview of: - Similarity - Specificity - Highlighting repetitions, breaks and inversions. ] </br> .image-50[  ] ] .pull-right[ .left[ A non-exhaustive list of tools for making dot plots: - MUMmer dotplot - Chromeister - D-genies (not yet available into Galaxy) ] </br> </br> </br> .image-50[  ] ] --- # Tips - The quality of an assembly is often validated by using other data from the same individual or from other individuals (RNA-Seq alignment, Hi-C alignment, DNA-Seq alignment,...). - The positions of the telomeric repeats in the chromosome assemblies are also of interesting to evaluate the correctness. - The identification of organelles (mitochondria, chloroplast,...) can also inform us about the quality of the assembly in terms of completness. However, the structure of the organelles may lead the assembler to think that they are repeats and he discards them. - In the case of diploid organisms, one of the classical problems of assemblies is the conservation of the two haplotypes. We obtains particular BUSCO / kmer / assembly size metrics that can be corrected by removing, "purging", the haplotigs. --- ### <i class="fas fa-key" aria-hidden="true"></i><span class="visually-hidden">keypoints</span> Key points - We learned that it is essential to control the quality of an assembly - We learned that there are several quality criteria and tools to enable this assessment - Certain quality criteria are expected at the time of publication --- ## Thank You! This material is the result of a collaborative work. Thanks to the [Galaxy Training Network](https://training.galaxyproject.org) and all the contributors! <div markdown="0"> <div class="contributors-line"> Authors: <a href="/training-material/hall-of-fame/abretaud/" class="contributor-badge contributor-abretaud"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/abretaud?s=27" alt="Avatar">Anthony Bretaudeau</a> <a href="/training-material/hall-of-fame/alexcorm/" class="contributor-badge contributor-alexcorm"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/alexcorm?s=27" alt="Avatar">Alexandre Cormier</a> <a href="/training-material/hall-of-fame/stephanierobin/" class="contributor-badge contributor-stephanierobin"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/stephanierobin?s=27" alt="Avatar">Stéphanie Robin</a> <a href="/training-material/hall-of-fame/r1corre/" class="contributor-badge contributor-r1corre"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/r1corre?s=27" alt="Avatar">Erwan Corre</a> <a href="/training-material/hall-of-fame/lleroi/" class="contributor-badge contributor-lleroi"><img src="/training-material/assets/images/orcid.png" alt="orcid logo"/><img src="https://avatars.githubusercontent.com/lleroi?s=27" alt="Avatar">Laura Leroi</a> <a href="/training-material/hall-of-fame/chklopp/" class="contributor-badge contributor-chklopp"><img src="https://avatars.githubusercontent.com/chklopp?s=27" alt="Avatar">Christophe Klopp</a> </div> </div> <div style="display: flex;flex-direction: row;align-items: center;justify-content: center;"> <img src="/training-material/assets/images/GTN.png" alt="Galaxy Training Network" style="height: 100px;"/> </div> <a rel="license" href="https://creativecommons.org/licenses/by/4.0/"> This material is licensed under the Creative Commons Attribution 4.0 International License</a>.